Security folks tend to become suspicious of applications that move data beyond the environments they manage, as it may seem safer to run AI models on self-managed infrastructure. But is it really a better choice than using LLM APIs and applications that force you to send data into the wild? The answer depends (shocker). Specifically, it depends on which models you’re running and how effectively you can monitor them.
What Is a Self-Managed AI Model?
When we talk about self-managed models, we’re referring to AI models (including LLMs) that you deploy and run on your own infrastructure. Rather than sending data to external APIs or using managed AI services, you take responsibility for the entire inference stack. While GPU farms are required to run larger models, smaller and more efficient models can run even on a developer’s own workstation.
Why self-managed? Organizations might use self-managed models developed in-house (either from scratch or based on existing open-source components). But even if you’re running a commercial or prebuilt open-source model, you might choose to self-host so as not to compromise data privacy. That’s because running models on your own infrastructure keeps sensitive information under your direct control.
Self-managed models increase control over data security and lower compliance risk (e.g., regarding GDPR data residency demands), making it particularly valuable for highly regulated industries such as finance, healthcare and government agencies. They also deliver performance benefits, including reduced latency and potentially lower costs.
Let’s consider a basic LLM-powered application that analyzes the company’s data to answer user requests – to extract insights from meeting transcripts, for example. If the company uses a model as a service (e.g., OpenAI API), then the MaaS will include some application logic that pulls the relevant data and sends it to the LLM to work its magic, as seen in figure 1.
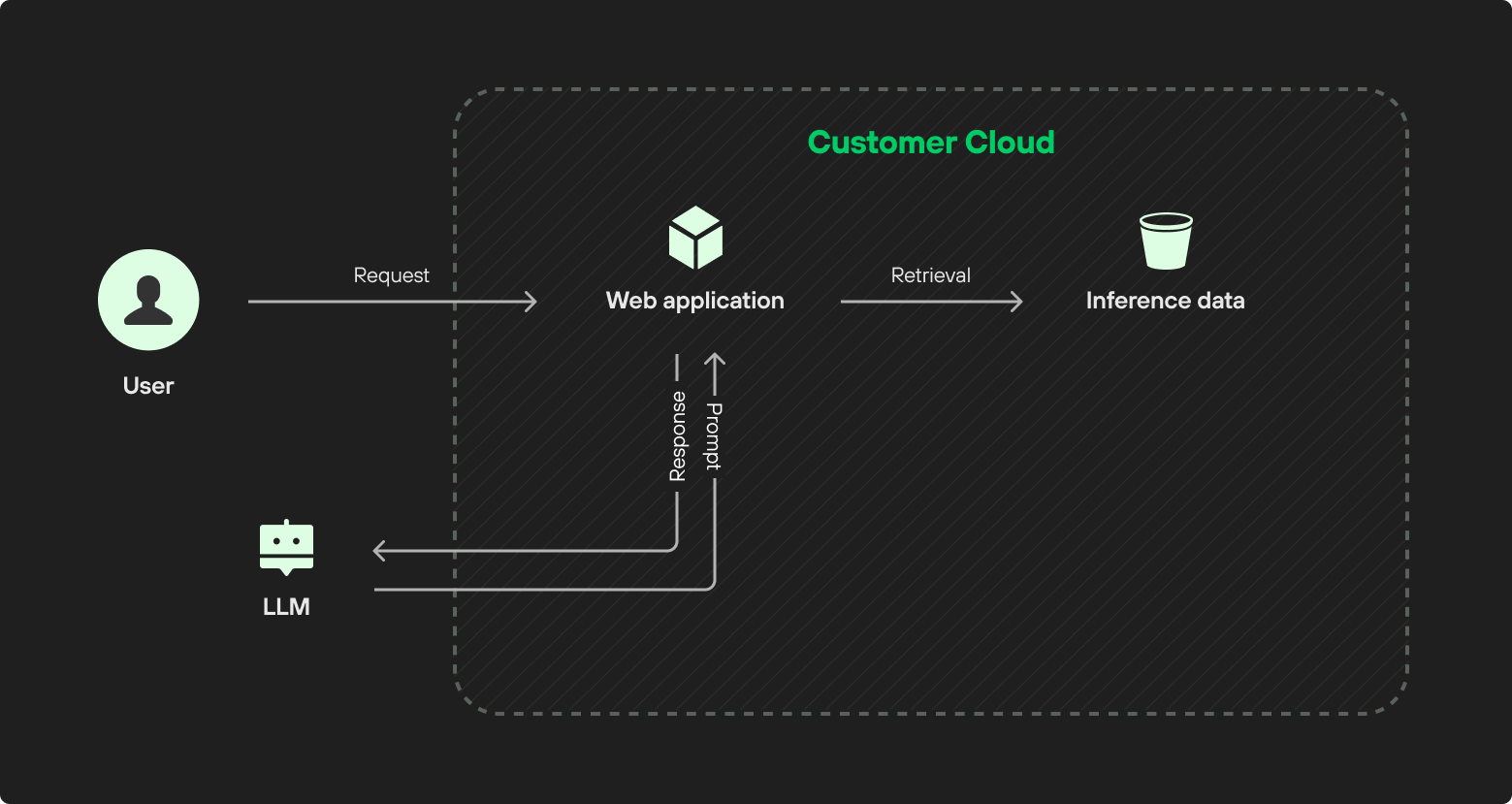
If there’s nothing sensitive in these transcripts, it might be fine. But if some sensitive data has snuck in, there could be issues with sending it to third parties (even if the third party is fully trusted).
In a self-managed deployment, everything resides within the customer’s cloud or on-premises environment.
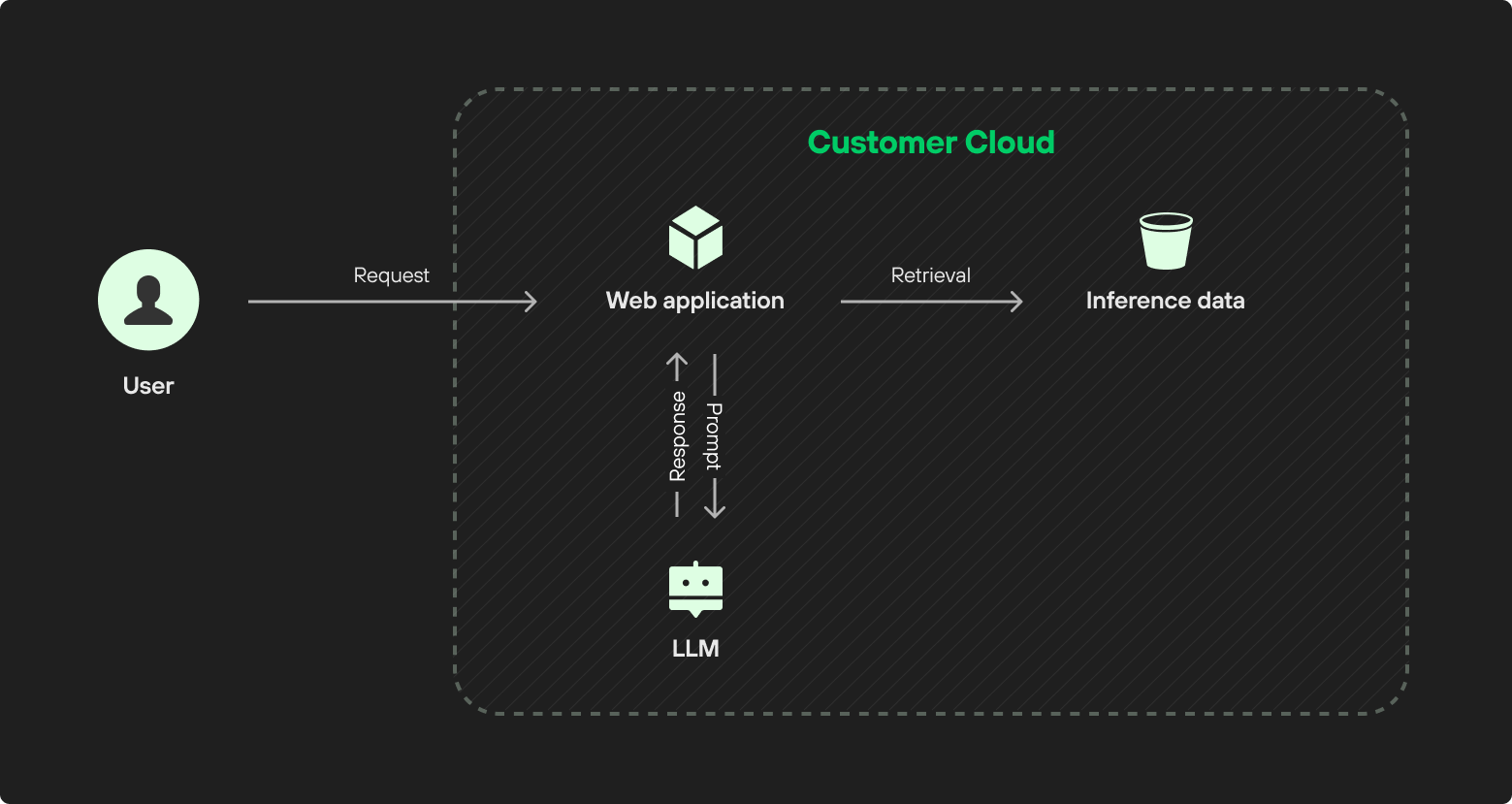
Self-managed doesn’t equal open source. Many self-managed setups are built on open-source (or open-weight) models, since this often fits with the broader goals of maintaining control over costs, data and deployments. Models are available through online repositories such as Hugging Face and GitHub. Mixtral (by Mistral) and Llama (by Meta) are popular open-weight choices in the LLM sphere, but proprietary models like Google’s Model Garden can also be deployed on infrastructure you manage.
We’ve summarized the different model creation and deployment options in the table below.
| Who built the model? | Where is the model running? | Who is managing the infrastructure? | Category |
| Your company | In your environment (e.g., private cloud on AWS) | You | Self-managed |
| Another company (e.g., foundation models such as Claude or Gemini, open-source models such as Llama) | In your environment | You | Self-managed |
| Cloud provider
(e.g., Amazon Bedrock, Google Vertex) |
Managed | ||
| In the model provider’s environment | Model provider (e.g., Anthropic API, OpenAI API) | SaaS | |
What Are the Security Implications of Self-Managed AI?
As mentioned above, hosting AI models in your own environment might seem less risky than sending the data to third parties. But it’s more nuanced than that. Models running on managed services and SaaS tools can be monitored through centralized tools such as Amazon IAM or via the admin features of the SaaS tool being used. This means IT and security have some level of built-in visibility into which models are running and who can access them. This isn’t the case with a self-managed model, which any developer can install and run on a virtual machine.
The relative opaqueness of self-managed infrastructure, which often leads to problems such as shadow data, can result in similar challenges when it comes to AI models. We often encounter three main types.
Shadow AI
AI governance starts with knowing where and how AI is being used. And self-managed models are inherently harder to discover than either API-based services or models running via managed services. When teams deploy models on virtual machines or container environments, these deployments often stay under the radar of traditional security monitoring tools. In highly distributed environments and with the use of smaller and more efficient models, there are plenty of nooks and crannies where developers can deploy a model that goes undetected.
Untracked AI deployments make it impossible to maintain an accurate picture of your AI attack surface. For example, a model used to analyze sentiment in customer support tickets might be handling personally identifiable information (PII), which requires a stricter level of oversight and a different set of controls. Not knowing that the model exists is a recipe for trouble.
Security teams need to understand which models are processing sensitive data, which have access to internal systems, and how data flows between AI components and other infrastructure. Self-managed models make this harder to do.
Supply Chain Risks
The most immediate threat posed by self-managed models occurs when malicious models masquerade as legitimate ones. Public repositories host millions of models from various contributors, and not all of them are benign. Some models contain embedded malware that executes when loaded, while others are designed to exfiltrate data during inference.
A compromised model could contain backdoors that trigger specific input patterns, or it might subtly modify outputs that leak information through steganographic techniques or unusual response patterns.
Unlike traditional software where source code can be reviewed with standard static analysis tools, AI models are typically binary artifacts like PyTorch or ONNX files. While these models can still be scanned and analyzed, this requires specialized tools, since conventional SAST tools aren't equipped to understand neural network structures or weight-based behaviors. And when you run models on your own servers, you skip the built-in validation steps that cloud providers have added to their systems (although it’s worth noting that these are also not bulletproof).
Use of Unsanctioned Models
Even legitimate models can create security and compliance headaches if they haven't been vetted for organizational use. Developers often experiment with new models to solve specific problems or improve performance, and these experiments can quickly move into production without proper security review.
The rapid pace of AI development compounds this issue. As we’ve written elsewhere, new models appear weekly, and the temptation to take them for a spin is high and typically easy to realize.
For example, an organization might deploy a language model trained on scraped web data to assist with market research. Unlike managed services that typically include built-in safety measures, self-managed models rely entirely on your implementation of these controls. If these controls aren’t in place, the model might reproduce other companies’ intellectual property in its query responses; this can then find its way into public-facing materials and create liability risks for the organization.
How Cortex Cloud Can Help
Cortex Cloud AI-SPM provides end-to-end visibility and risk analysis for AI-powered applications. For self-managed models, Cortex Cloud offers several tools to establish governance and reduce risks, including:
- Model discovery: Cortex Cloud continuously scans managed and unmanaged infrastructure to detect AI model deployments, including open-source models, providing a comprehensive, up-to-date inventory of AI models and LLMs running in your cloud environment.
- Infrastructure relationship mapping: Cortex Cloud traces data flows between discovered models and cloud resources by analyzing network traffic patterns, IAM permission grants and storage access logs. For example, if an application running a fine-tuned language model is granted “read” access to an S3 bucket containing customer data, the platform maps this relationship and flags potentially excessive permissions.
- Identifying and removing models that are no longer active: Reduce risk and cloud cost by eliminating unused models that expand the attack surface, introduce compliance gaps and consume unnecessary resources. Their removal helps security teams quickly reduce exposure and improve operational efficiency.
- Model intelligence: Cortex Cloud pulls metadata from Hugging Face and similar repositories, including the number of downloads, platform upvotes, license, author and component tags. This data helps security teams evaluate the risk level of a community-maintained model at a glance (although it doesn’t replace the need for more thorough vetting and verification).
To learn more, schedule a demo with a Cortex Cloud expert.