Kubernetes has become a center of modern cloud-native applications. Its complex architecture and dynamic nature, however, continue to introduce new security issues. Though strides have been made in addressing the challenges, managing entities and their access rights remains daunting.
In an extensive IAM study, Unit 42® found that 99% of cloud users, roles, services and resources were granted excessive permissions. It’s safe to assume that the numbers for Kubernetes clusters are similar. Kubernetes has no internal centralized directory for managing its identities and uses a relatively complex permissions structure with resources and sub-resources, special verbs, group inheritance and a number of other features. These complexities make the task of determining which entities exist, what access they have, and what access they need overwhelming to say the least.
In this blog post, we examine authorization auditing and look at the challenges of identifying entities that have access to the cluster. We explore methods to enumerate the specific access rights or permissions they maintain within the cluster, as well as tackling the challenge of identifying each entity’s required permissions to perform their business-intended tasks.
Finally, with our sights set on helping you achieve least-privilege status within your Kubernetes clusters, we introduce KIEMPossible, an open-source tool designed to simplify Kubernetes infrastructure entitlement management (KIEM).
The Problems
Who Has Access?
Users, groups and service accounts are the various entities in a cluster that can be granted permissions. Additional integrations such as AWS roles, GCP service accounts and EntraID entities enable assets external to the cluster to gain access. However, these integrations take place by using Kubernetes native assets (i.e., service accounts, roles and bindings). Service accounts are intended to be used by workloads within the cluster, while users are utilized for accessing the cluster externally.
The problems arise when looking at users and groups. While service accounts exist in Kubernetes and can be retrieved directly through a simple API call, users and groups cannot, since Kubernetes does not maintain a directory. These entities are considered external identities, authenticated through any number of means (depending on cluster configurations) such as certificates or cloud IAM services. As such, it is not trivial to compile a list of entities with access to a given cluster.
What Access Do They Have?
Kubernetes offers multiple methods for granting permissions to entities, such as roles and bindings – the core method – group inheritance, and external integrations (e.g., access policies in EKS).
Roles and ClusterRoles are essentially policies that hold permissions, defining sets of actions and resources that are allowed. ClusterRoles can be scoped to an entire cluster using ClusterRoleBindings, or limited to a specific namespace within a cluster using RoleBindings. Roles can be scoped only to specific namespaces within a cluster using RoleBindings. Bindings specify the Role or ClusterRole and the entities to which they will be bound, such as users, service accounts and groups.
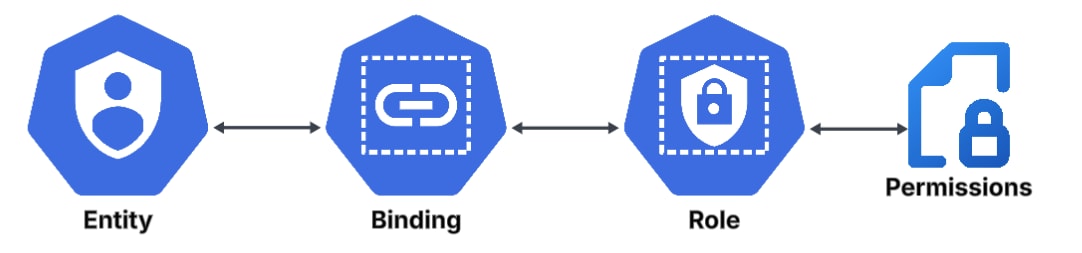
When groups are bound to roles, discovering who effectively received the permissions can be a difficult task. As previously mentioned, Kubernetes does not expose an API that will allow us to just “list entities in group”, and as such, we must revert to different methods.
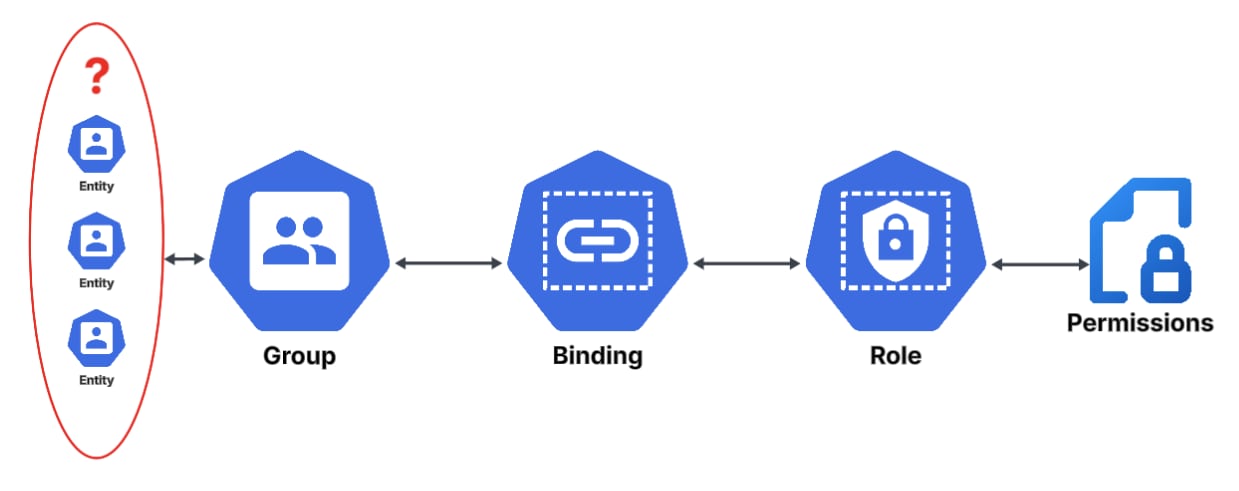
What Access Do They Need?
The final challenge we will tackle in this blog is identifying the required permissions for each entity to perform their required business-intended tasks. Permission management in Kubernetes is complex even without adding an attempted mapping of each entity’s required permissions. With that said, there is an added challenge: How can we account for dynamic changes, both of required permissions and of the permissions themselves?
The Approach
Entity Discovery
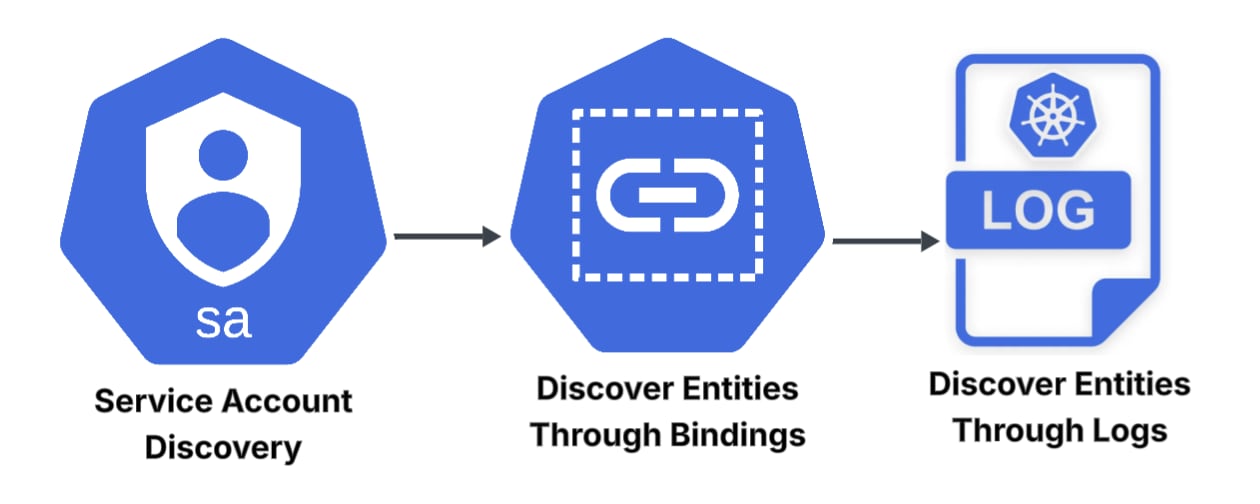
When tackling entity discovery, we can separate the process into two – service accounts and users and groups. Service accounts exist as objects within a cluster, and an API is exposed to retrieve them. As such, retrieving all service accounts in a given cluster is as simple as an API request.
The approach for users and groups is slightly different. As mentioned, they do not exist as objects within the cluster. However, there are a few breadcrumbs within the bindings. As the bindings mention each entity to which they bind and its type, we can iterate through all of the bindings in a cluster, extracting every user and group. While this method is a step forward, there’s still a blind spot. Users and groups don’t appear in the bindings directly but rather get their permissions solely from group inheritance.
We can partially solve the issue by going through the logs and comparing the entity performing an action in each entry to our list of known entities, marking each unknown entity as new. Additionally, the groups claim (which we expand on in the next section) enables us to discover new groups using the same method. The reason this is only a partial solution is that it relies on users taking action within the time span we examine in the logs. Users that don’t will still be invisible to us (i.e., shadow users). But, if we apply this method consistently, we'll discover these users as soon as they take action.
Permissions Discovery
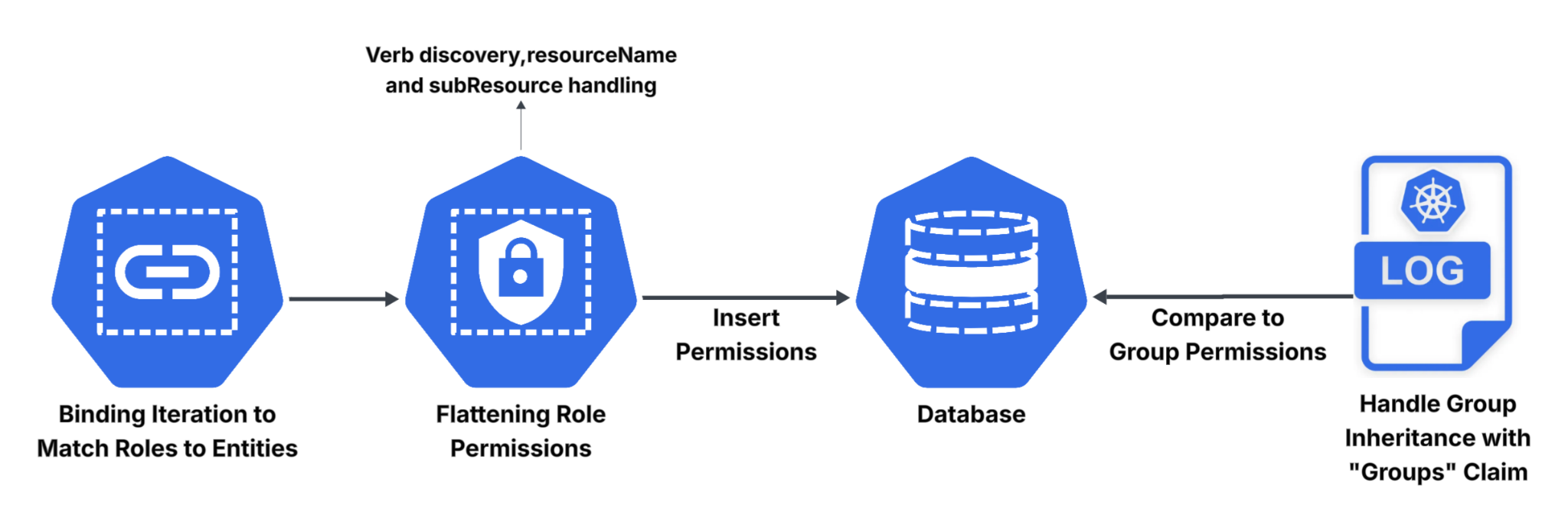
The approach we adopted in identifying cluster entities’ permissions includes iterating over each RoleBinding and ClusterRoleBinding, matching entities to Roles and ClusterRoles at the different scopes. We then break down permissions for each role into the most concrete, explicit actions possible. For example, a broad rule like “* on pods at the cluster level” is expanded into a list of specific permissions such as “get pods in namespace X”, “delete pods in namespace Y”, etc., for every verb and every namespace. This flattening gives us a detailed, precise view of all real permissions, making it easier to spot risky capabilities and later comparing them to the actions performed within the cluster.
We must ensure a number of aspects during this process including accurate verb discovery, resourceName usage and subResources. Verb discovery enables us to match only the relevant verbs for each resource type when flattening wildcard verbs (such as impersonate or bind). When defining roles, permissions can be granted for specific resources using resourceNames, which we must take into account as part of the scope.
Some resources contain subResources within them, and the permissions for those may hold different meanings and implications than intended. We must also ensure that if a permission is granted solely on a subResource, we do not accidentally insert it into our database as being granted on the parent resource.
Entities that don't exist in the bindings (i.e., entities we discovered through the logs as discussed previously) require a different solution. The solution we identified is the groups claim in the log events. The groups to which each entity belongs are reflected in the logs, allowing us to map group inheritance.
For each permission pertaining to a group (using its bindings), we also insert a permission for the entity discovered in the log event. We also can use the logs to map permissions granted through access entries in EKS. Access entries have predefined permissions, and the specific access entry is mentioned in the log events. As such, we can map the specific permissions each access entry grants (which requires a combination of AWS APIs to determine the scope of the granted permissions).
Analysis
Our last challenge is identifying the required permissions for each entity. Our approach was to examine the logs and map the actions each entity makes against its permissions. The logic behind this approach is that permissions that weren’t used for X number of days (the specific number is contextual – you know your cluster best) are simply not needed. The approach is quite well suited to service accounts (and machine accounts in general). They tend to run either on a schedule or based on certain triggers, and as such, it’s fairly safe to say that unused permissions are unnecessary. Human identities, on the other hand, tend to be more sporadic with their actions and as such, we must be cautious with this approach. One exclusion to this pattern, which could potentially break the assumption of machine identity patterns being anticipatable, is the inclusion of AI entities (e.g., agents). The assumption is that their behavior patterns would be mixed, however, there is insufficient research thus far around this area.
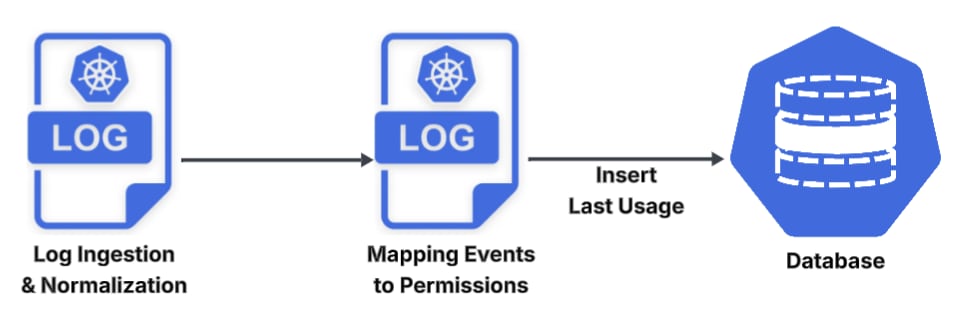
This solution requires integration with the relevant log services to ingest the logs. The logs must also be normalized to be able to handle them consistently. Additionally, we need to handle the differences between the providers.
It’s important to understand the limitations of this approach. In managed clusters (e.g., AKS, EKS, GKE) we can’t specify the exact logs to be collected and the visibility to see the configurations. This is because the configurations are part of the API server manifest configurations located on the control plane nodes, which are not accessible to us when using managed cluster services.
During testing, we deployed every possible resource and performed every relevant verb for each one on AKS, EKS and GCP. At the time, every action was logged at some level (we didn’t check which level as it was irrelevant for our use case), however, this is subject to changes at the cloud providers’ will, while consumers maintain no visibility to these changes. Additionally, direct interactions with the Kubelet component aren’t logged, which represents a gap. Users that get permissions only through group inheritance and don’t perform actions within scanned timeframes won’t be visible through this approach. In GCP, the log format excludes the groups claim, and as such, group inheritance isn’t supported for GCP.
Introducing KIEMPossible
KIEMPossible is an open-source, Golang-based tool for KIEM. It offers visibility to entities, permissions and their usage within a cluster, and is designed to help identify and minimize identity-related attack surfaces in Kubernetes. Current support extends to AKS, EKS, GKE and self-managed clusters. It was designed to raise attention to an area that we feel doesn't get enough awareness.
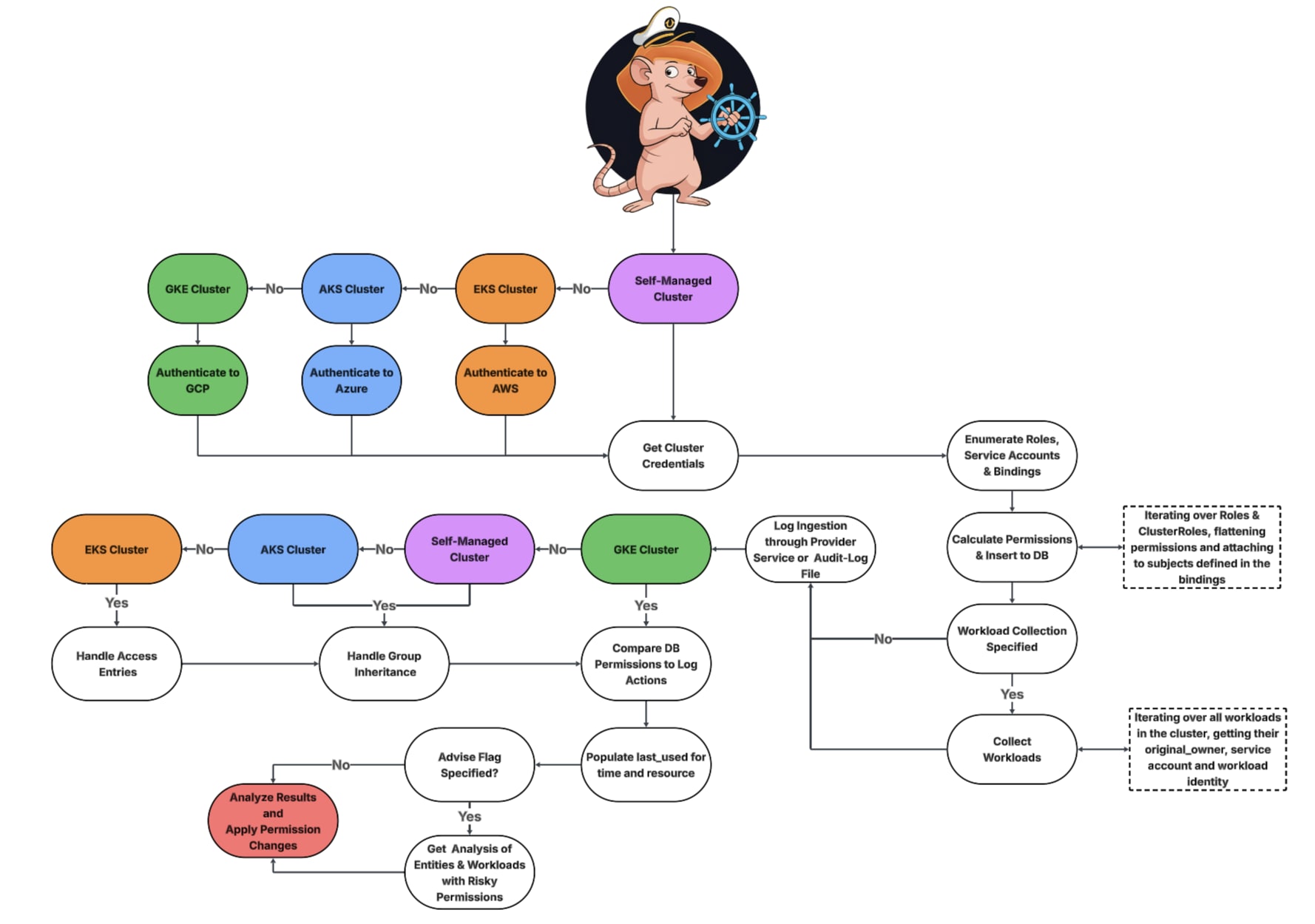
The tool creates a database (rufus) with two tables. One table contains all the discovered permissions in the cluster and their last used time and resource. The second table contains workload mappings to their related identity and original_owner. The tool’s repository includes a descriptive readme with information regarding the results and insights, additional information on required permissions for each scenario, how to run the tool, and more. Figure 5 below diagrams the flow when running the tool.
How Cortex Cloud Can Help You Secure Your Cluster
Cortex® CloudTM offers the KSPM module dedicated to protecting your Kubernetes clusters. KSPM provides full visibility into the resources within your clusters in a unified view that enables you to review the assets in a broad manner while providing the granularity of examining individual assets and their configurations. It also provides prioritized and actionable security insights, spanning identified vulnerabilities or malware to discovered secrets and misconfigurations. What’s more, you can now use the open-source KIEMPossible to reduce the identity attack surface within your clusters.
Want to hear more? See Cortex Cloud’s KSPM for yourself with a demo customized to your interests.
FAQs
What is the biggest challenge to applying least access privileges in Kubernetes?
There are three main challenges: Entity Discovery, Permissions Discovery and Required Permissions Discovery. Kubernetes has no internal centralized directory for managing its identities, making the discovery process for users and groups quite complex. Due to the group inheritance concept, external integrations and complex concepts within the Kubernetes permissions structure (such as special verbs and sub resources), pinpointing individual entities’ specific permissions can present a challenge. As with any system, discovering the required permissions each workload requires for its intended business purpose has challenges such as dynamically changing requirements and/or permissions, complexity in understanding and mapping actions which the entity requires vs the minimal permissions required.
How can Cortex Cloud help with Kubernetes security?
Cortex Cloud’s KSPM module allows full visibility into your clusters, both through a holistic unified overview, and a granular resource-by-resource view. Its prioritized and actionable security insights help you understand and mitigate the biggest risks to your clusters. Lastly, the open-source tool KIEMPossible helps you reduce the identity attack surface within your clusters.
What is KIEMPossible?
KIEMPossible is an open-source tool that allows visibility on entities, permissions and their usage within Kubernetes clusters and is designed to help identification and minimization of identity-related attack surfaces in Kubernetes.