Network intrusion prevention systems, referred to as IPSs, have long been considered a critical component of any network infrastructure.
Here is how a network IPS works. Vulnerability-based protections detect and block exploit attempts and evasive techniques on both the network and application layers, including port scans, buffer overflows, protocol fragmentation, and obfuscation. Protections are based on both signature matching and anomaly detection. Anomaly detection decodes and analyzes protocols, and uses the information learned to block malicious traffic patterns. Stateful pattern matching detects attacks across multiple packets, taking into account arrival order and sequence.
Being part of a larger security program or platform, the links in Lockheed Martin’s Cyber Kill Chain that IPS set out to cut are Deliver and Exploit.
Network IPS solutions come with thousands of signatures. These signatures can range from severity levels of informational to critical with many in between. All of the signatures are useful; however, some need more context. This is what the tuning process is all about.
It is recommended to enable all of the signatures in alert only mode during the initial deployment phase, which should last approximately one week. These signatures are what you’ve paid for, so you should leverage as many of them as possible.
The perception of IPSs is that they are noisemakers, difficult to configure, and difficult to manage. Some of this may be the case. Effort is required to deploy an IPS. The purpose of this guide is to provide a methodology for tuning IPS alerts for maximum value of as many signatures as possible while being able to identify actionable incidents.
The best practice for tuning IPS alerts is to take a hierarchical approach. Start with investigating the signatures that trigger most. Alternatively, you may want to focus on the High and Critical severity ones first. From there, determine what the source and destination IP addresses should be doing in the environment. Finally, either fix the problem or create a filter. Fixing the problem may include making configuration changes on the source, destination, or other host. Fixing the problem may also mean preventing certain types of traffic or implementing a filter. Determining the purpose of the source and destination IP addresses by working with internal teams who manage them are going to be consistent tasks, which can take time. Play nice and make friends with these people!
At some point you will want to configure filters to ignore certain signatures in certain circumstances. The team that manages the IPS must take a leadership role and make more recommendations than ask questions when it comes to working internally to filter alerts. A process must exist before you start that includes:
- How long does the security team need to wait for responses prior to filtering?
- How are filters documented (in the IPS filter, in the IT ticketing system, etc.)?
- When changes can be implemented?
Now we can walk through a few examples using some real data from a Network IPS deployment prior to any tuning. The appliance has been in this particular environment for two weeks.
Step 1: Report on the Alert Data
There are many ways to report on which signatures are triggering and the frequency of the triggers depending on the IPS you are using. You will often find this information by looking at a dashboard, looking through the logs, or running a report. Your goal in this step is to identify the names of the alerts being triggered, the severity of those alerts, and the number of times they are being triggered.
Depending on your preference, you may want to focus on the High to Critical severity alerts by number of triggers. Or you may just want to focus on every alert by the number of triggers.
Here is an example of pulling the top 25 alerts by count.
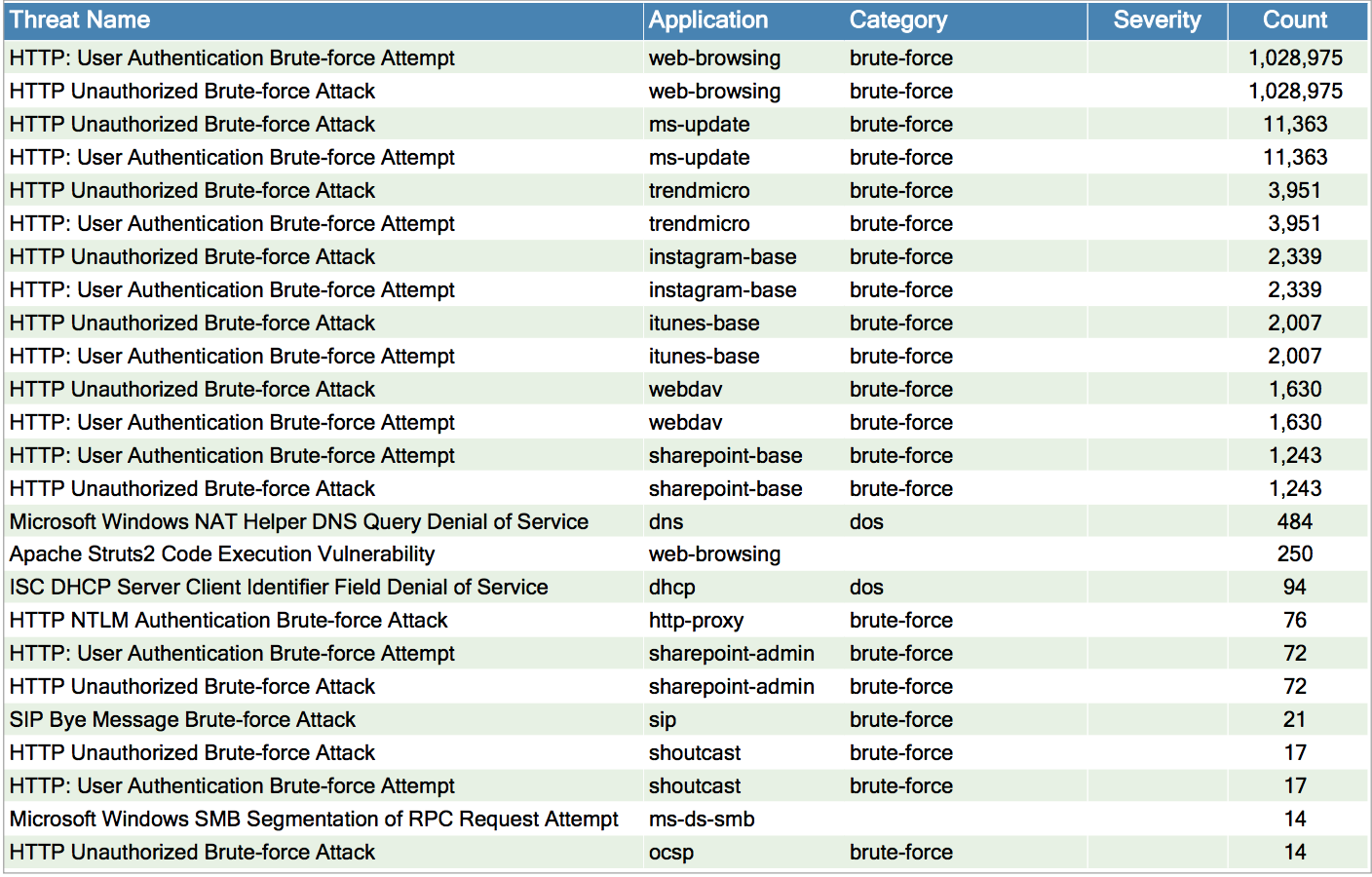
Step 2: Drill Into the First Alert
The goal of this step is to answer the question: when the sources and destinations triggering the alert are observed, is this worth investigating? If it’s something that is clearly a problem that needs to be resolved, you clearly need to take that path. When the answer is no, you would move to the next stage and tune the alert.
The first two signatures in the list have the same alert count, so are likely related.
- HTTP: User Authentication Brute-force Attempt
- HTTP: Unauthorized Brute-force Attack (using web-browsing)
Step 3: Understand the Signature and Frequency
The alert description and severity let you know how urgent it is to investigate the issue. The severity on these is High.
It is, however, important to move through the rest of these steps, regardless of severity. The source and destination IP address will add context that is more concerning. For example, if you see an informational alert for DNS lookups, you may initially think that those happen all day long and are, therefore, too informational and irrelevant. If you have specified two unique name servers for all of your devices to use, it would be strange if a name server outside of the ones you provide is being used (it shouldn’t be allowed but that’s a least privilege story). Tuning the signature to only alert if a device is using a name server that is not yours turns this informational event into something much more critical.
Reading into the descriptions of each shows that the definition of the signatures is quite similar. The first brute-force attempt is looking for a certain number of authentication requests between a pair of IP addresses. The second brute-force attack is looking for the same thing and also checking to see if the target is rejecting the logins with an error.
Because the description and the count of these alerts are so similar, we may be able to investigate both of them at the same time.
Step 4: Investigate the Source and Destination IP Addresses, and Application
The source and destination IP addresses add an important piece of context. If both are internal, it is most often a configuration or informational issue for an alert like this. The exception would be if the signature identifies hacking or malware activity, but even those can sometimes be strange (read poor) application programing that looks like something bad. We often see buffer overflow-type attacks fall into this strangely coded category internally.
When we drill into each of the alerts, we find that the same source and destination IP addresses are found consistently. Both addresses are internal. We can definitely investigate both of these signatures in parallel.
The application in this case is web-browsing, which means the source IPs are browsing or making HTTP GET requests to the destination IP.
If you are unsure what the IP addresses are, there are a variety of ways you can get more context:
- Nslookup <IP address> may provide you with a descriptive enough hostname.
- Browsing to the IP address in a web browser may display a familiar page.
- Connecting to port 80, 443, or 25 on the host may provide more information on what the host is.
In this particular case, we determined that the source of all these alerts was a server. The destination address is a proxy server (that we are working on removing from the environment because proxies are dead!).
Step 5: Determine a Course of Action
By working with the server and proxy administrators, we determined that someone had misconfigured the proxy settings on the server. The server was attempting to use the wrong account to authenticate to the proxy.
The course of action was to fix the setting on the server. The server team was motivated to make the change quickly because things weren’t working because of this. Once completed, all of the alerts stopped triggering. There was no need to make changes to the IPS in this case.
And, in one shot, we took care of 98% of the alerts.
The next 12 alerts make up over 98% of the remainder.
- HTTP: User Authentication Brute-force Attempt
- HTTP: Unauthorized Brute-force Attack
using ms-update, trendmicro, instagram, webdav, and sharepoint
The descriptions are the same for all of them. The alert count is also the same just like the first investigation. This means that the same source IPs appear to be trying to log in repeatedly to the same destinations, and they are failing the authentication. When investigating the source and destination IP addresses, they are all internal, except for Instagram.
More diligence is still required to figure out why each of these is triggering, and the application identified will help lead us to a solution. Following is a breakdown of each of the same signatures triggering broken out by application.
- MS-update – The source IP addresses are remote VPN hosts connecting to the network and having an issue authenticating with the internal Microsoft Update server. Speaking with the firewall team, there is a known issue with the VPN client that needs a patch on these systems. It’s worth waiting for the patch to be applied and reporting back to that team on their progress before filtering these alerts. There is a planned maintenance to patch these systems over the next two weeks, so no point in filtering these alerts right now.
- Trend Micro – These are internal hosts communicating with the internal OfficeScan server. This issue was discussed with the desktop support team who helped determine a user account had been disabled on many of the systems leading to these HTTP 404 errors. They were happy that the issue was identified and are working towards implementing the fix. No need to filter these alerts, as they will go away over the next week, once the user account information is updated.
- Instagram – The source IP addresses are all on the WiFi subnet. These are likely phones and tablets whose passwords were changed on the website and not updated on these apps. Because Instagram is not a critical application for this environment, we will create a filter with the source being internal networks, the application being Instagram, and the associated HTTP brute-force signatures, with the action to ignore.
- WebDAV/SharePoint – The source IP addresses are internal. The destination IP appears to be SharePoint, based on the DNS name. When drilling into the alerts, we can see that the URL being accessed is a SharePoint URL. According to the SharePoint administrators, that particular URL contains areas on the page with objects that only a small group of people have access to. The SharePoint team doesn’t want to change the site layout based on the business owner’s requirements. As a result the case will be escalated, documented, and a filter applied. The filter will include the internal source subnets, the destination URL, and these HTTP brute-force signatures, with an action of ignore.
Conclusion
There is always a trade-off of risk for functionality when tuning signatures. On the one hand, you want to use every signature for everything. On the other hand, it is important to tune out noise to make the relevant alerts noticeable.
In these example cases, we were able to find many misconfigurations in the environment that resulted in opening tickets to document the issues and holding them open until resolution. If a filter was the only route, we would no longer be able to see if an internal source address is doing an HTTP brute-force attack on these particular web servers using those specific applications. We are trading that functionality based on the fact that it is happening too often for us to find anything useful in those logs for that circumstance. If an internal host is doing an HTTP brute force, there will be other indicators of compromise that we will rely on, such as the source host getting compromised, malware being transferred to the source host, and the source host communicating with a command and control server.
There will be many signatures that require longer investigations, many Internet searches, and packet captures to validate. Once this process is complete, you should be safe to enable blocking on the High-Critical severity signatures and let the computer do its job of protecting the environment by preventing malicious behavior.
By tuning out alerts that cannot be eliminated by fixing something on the source or destination computers, we bring the IPS alerts to a useable level so we can focus on monitoring for real threats.