In my previous blog post in the Exploitation Demystified series, we learned how memory corruption exploits are implemented using stack-based overflow vulnerabilities. Let’s talk now about a main alternative path: heap-based vulnerabilities.
What Is the Heap?
An operating system (OS) allocates memory to a computer program, with respect to the size of the data this program consumes, which is either known before or determined at runtime. We have already introduced the stack, which is the OS allocation mechanism to the former. We will now get to know the heap, which serves the same allocation function to the latter.
The heap is the memory pool from which dynamic data requests are fulfilled. From a vulnerability/exploitation perspective, the two material differences between the stack and the heap are:
- Heap memory must be requested explicitly. The program asks for a memory chunk in a certain size and gets a pointer to the first address of this chunk. The program should also free this chunk when it has completed its task. The request-free logic is the root cause to the common vulnerabilities class of use-after-free/double –free.
- The heap is significantly larger in size than the stack. This makes an accurate prediction of the shellcode's address much more complicated than in the stack. This complication is the development driver of the heap spray exploitation technique, which is practically common practice in most to all heap-based exploits.
Memory Corruption Recap
Let's remember what we have learned so far about memory corruption exploits. This class of exploits involves placing a shellcode into a data input file, which is crafted to trigger a vulnerability in the processing application. The vulnerability renders a foothold in the process memory space, which the attacker leverages to redirect the execution flow towards the shellcode address. I’ll explain how both the Overwrite and Redirect parts are implemented on the heap.
Heap-Based Vulnerabilities Overview
In this post we will not deep dive into the subtleties of heap-based vulnerabilities. This is because the role of vulnerabilities in the exploitation lifecycle is to enable the initial address overwrite. From a security standpoint, this initial overwrite can hardly be prevented (except by a vendor patch). But proactive prevention can be applied to the Redirect and Execute parts of the exploits, so we will focus on these.
For our purposes, it suffices to know that there are two main groups of heap-based vulnerabilities: heap overflows and use-after-free. Let's see what address is overwritten in each of these groups.
Heap overflows take advantage of the heap internal structure. Consecutive heap requests generate consecutive memory chunks. Each chunk consists of a header, which contains the chunk's metadata, and the actual memory space in the requested size. Heap overflow vulnerabilities will overflow the memory space and overwrite the next chunk's header.
Use-after-free vulnerabilities take advantage of the explicit call/free feature we have previously described. As we have explained before, dynamic memory requests render a pointer to the first address of a newly allocated chunk. If this pointer maintains validity despite the pointed object being freed, attackers can overwrite it to point to their own code (i.e., the placed shellcode). Use-after-free were the most exploited vulnerabilities on Windows 7 and later versions of Windows during 2015.
Heap-Based Exploitation Redirection – Heap Spray
Once the attacker is able to overwrite and control a heap address, the main objective is to resolve the shellcode's address. Due to the heap's size and allocation architecture, it is a much harder task relative to the equivalent stack scenario.
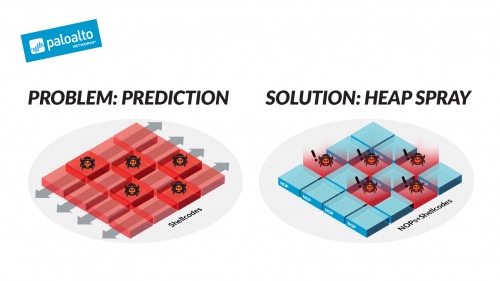
The Prediction Challenge
When placing a shellcode into a data input that is loaded to the heap, the attacker can know the addresses range in which this shellcode resides but not the exact address of the shellcode itself. I’ll explain the technique that has evolved in response to this challenge.
No Operation (NOP) Instruction
Attackers have overcome the prediction problem by loading multiple byte sequences and shellcode into the heap. The basic implementation of these sequences is to use NOPs. NOP stands for “No Operation”, and it instructs the CPU to move to and execute the instructions in an adjacent address.
NOPs can solve the heap address prediction problem. Consider a block that contains a NOP sequence, followed by a shellcode. Let’s assume that we fetch the CPU a NOP address. The CPU will simply move to the next address and so on and so forth until reaching the shellcode and executing it. The NOPs have exponentially raised the probability of a successful shellcode execution because, instead of just one “good address” (the shellcode’s), we have multiple.
Heap Spray
What I’ve just described is the basis for the Heap Spray technique, which, as the name implies, sprays a vast area in the heap chunk with many NOPs and shellcode sequences. The spray ensures that, no matter which address the execution flow will jump, it will end up with executing the shellcode.
Constant Evolution
Exploit writers continuously advance their heap prediction capabilities. The more accurate prediction capabilities are, the smaller a heap spray can get. The heap sprays that were featured in exploits from 2014–2015 are considerably smaller and more targeted than the ones from before this period.
Conclusion
In this post we have concluded our description of memory corruption exploitation essential building blocks. The three blogs together render basic understanding of what a memory corruption exploit is, and how it is implemented. Of course there is a lot more to learn and know on this vast subject, and we hope that this is the first step to encourage you to proceed onwards.