
Welcome to our new “Engineers at Work” blog series, where you’ll get an insider’s view of Palo Alto Networks engineers, what interests them and some of what they’re working on.
Passive vs. Active Monitoring
Before we dive into the benefits of active monitoring in a QA environment, it’s important to understand the differences between passive and active monitoring.
Passive monitoring is the traditional monitoring of a system without affecting any change to the system. Passive monitoring collects stats emitted by the system and then determines if the system is healthy or not.
As we build more complex and highly distributed systems, it becomes harder to interpret all the passive monitoring statistics being gathered and figure out the impact to the end-to-end functionality and experience (SLA or SLO). Passive monitoring tells us if our components are processing jobs, the rate at which they are doing so and the resources they are utilizing. It does not tell us if a system is processing the jobs correctly from a functional standpoint.
Active monitoring, in comparison, injects data or affects a change in the system, waits for the desired outcome, and then makes a decision on the health of the system based on that outcome.
Probe Architecture
Active monitoring can be set up as a set of simple functional tests, called probes, that run periodically in the production environment. Since most distributed environments are made up of micro-services, probes can be run against these individual services to determine their functional health and response times.
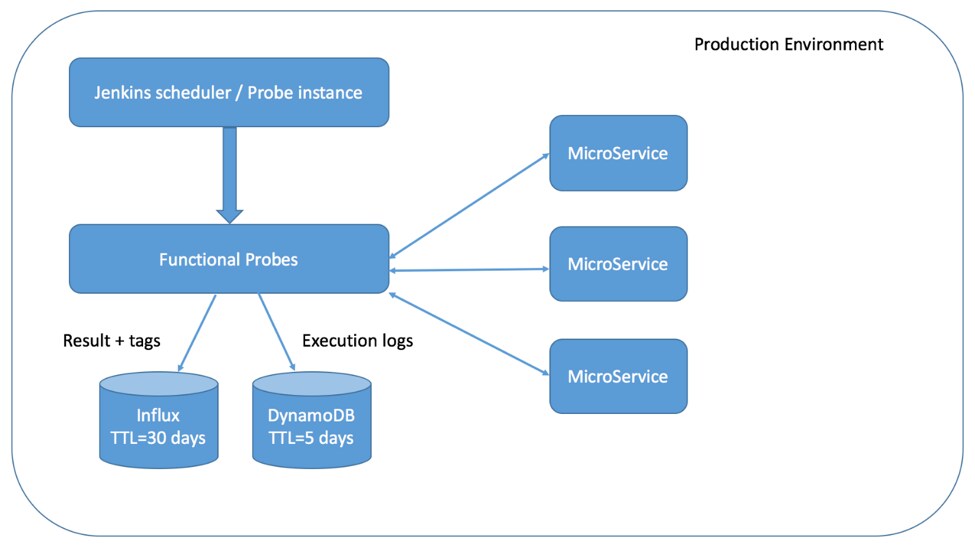
The probe system typically comprises:
- A scheduler (like Jenkins) to periodically run the tests
- Databases to record results and measurements
- Probe tests that are run by the scheduler
The probes themselves are just test cases executed for basic happy path testing. What makes them a little different from the QA test cases is the expectation of adherence to an agreed-upon SLO. The final results will record whether the probe test produced the expected results and whether we got those expected results on time.
Implementation and Deployment
Since probes are very similar to smoke tests or happy path tests that could already exist with QA automation, the temptation is to simply reuse them for probing. Any of the available test harnesses could be used, just like in automation, to implement them. In most cases, it would be prudent to use the same harness and libraries used by QA automation to develop probes and maintain reusability. However, a lot of QA automation is not production-ready in terms of robustness and compliance. Existing automation needs to be sanitized to make sure:
- No secrets are hard-coded or being read from a plain text configuration file. You can use a secrets manager like Vault (or your preferred system that is already in use) in the distributed environment to manage secrets.
- Unlimited access is not granted to the probe tests to access customer data. Probes will probably need their own access controls, with special users and roles created to limit what data the probes can see or modify.
- Deployment is similar to how other micro-services are deployed or upgraded. This will reduce the burden of maintaining a separate deployment procedure just for the probes.
For maximum effectiveness, it’s best to have probes developed and deployed along with their micro-service/feature counterparts, as most of the issues crop up immediately after deploying a new feature.
Monitoring
Probes need to have a monitoring setup, just like other services in production. Having alerts set up in a tool like Grafana will immediately grab attention when we have a SLO miss or a probe starts failing. Probes can also include functionality to send out emails with logs on failures or SLO misses to give more context to the monitoring alerts and aid easier debugging.
Utilizing Probes in QA
The reality of testing distributed systems is that all members of QA share a single setup in which they will run many unique tests. One test affecting the others becomes unavoidable and, in these cases, probes can be used as canaries to determine if the system is healthy before starting any of the tests. Also, probes act as a service-level smoke test where the health of the setup for every new build is periodically assessed. This ends up saving QA a lot of time debugging setup issues.
Moreover, probes can be pretty helpful while doing performance tests on a single micro-service, as they allow QA to study any domino effects on the other services downstream and ensure adequate resources during deployment.
Detections
Probes can be helpful in detecting a variety of issues that passive monitoring could miss, such as:
Incorrect Configurations
In most production environments, there could be a wide set of “correct” configurations that the service accepts. However, that may not be the configuration we actually want, or it may not produce the desired functional result. Configuration discrepancies can occur for a variety of reasons:
- Configuration overwrites with new deployment where custom configurations were not “saved” to be persistent.
- Configuration misses – new configurations not making it into deployment, forcing the micro-services into to a default configuration.
- Beta configurations not getting updated on GA.
Passive monitoring is limited in detecting functional failures caused by bad configurations – no alert is raised by the micro-service itself as, technically, there is no error. Since probes rely on a very specific functional result, they can immediately detect these issues as failures.
Silent Failures
Distributed systems are built to be resilient, meaning that many of failures are silent and can easily go unnoticed with passive monitoring. For example, if your micro-service is interacting with a third party application, the service is probably designed to account for disruptions and not fail. But this means that even when there are real issues, the micro-services would just silently move on to the next request or task.
With customers constantly submitting loads of tasks or data into the distributed system, a small percentage of failures can end up going unnoticed. Probes serve as a “customer” with a very limited data set or set of requests, where even one failure makes a bigger dent. A pattern of such continuous failures is easily recognizable and can point to problems with race conditions or timing-related issues.
Load Issues
Passive monitoring takes certain criteria, like CPU, memory, requests/sec and queue size, to measure the load on a micro-service. With every upgrade to a newer build or release, the services change in some ways, and these metrics could change – a service that was processing X requests/sec could now be processing Y requests/sec with the newer release. The change is not usually measured or updated as diligently in the passive monitoring system. In contrast, probes rely on an end-to-end measurement of SLO or SLA, which should remain relatively unchanged between releases and act as an additional alert system along with the passive monitoring. Superimposing probe SLO misses with passive monitoring stats can give a powerful analytics tool to determine the behavior of your distributed systems.
Conclusion
Active monitoring has had a huge impact on the way we develop, deploy, test distributed systems here at Palo Alto Networks. It has helped detect and provide a better context to a variety of failures, helping us recognize issues before they noticeably affect our customers. The added functional context around failures has also helped reduce our debugging times in both staging and production environments.
A tool that traditionally would have been restricted to the QA domain has benefitted development and production operation teams by finding things that nobody else was looking for.
We built Probes to solve real problems that we encountered in development and production. We would like to hear from anyone who has solved similar problems or people interested in this general area.
Palo Alto Networks engineers help secure our way of life in the digital age by developing cutting-edge innovations for Palo Alto Networks Next-Generation Security Platform. Learn more about career opportunities with Palo Alto Networks Engineering.