On February 28, the United States launched Operation Epic Fury. In the hours that followed, cyber risk related to Iran rose quickly, with coordinated activity emerging across regions from hacktivists and proxy groups. Moments like these require teams to strengthen their defenses and respond in real time.
In a surge, the hardest part is not seeing signals. It is deciding which ones to trust and acting before attackers turn minutes into impact.
Unit 42 is clear about what matters right now: implement strict out-of-band verification, increase response to threat signals around internet facing infrastructure, patch and harden fast, and train employees on phishing and social engineering. This post focuses on the part after the guidance. How you operationalize it inside the SOC.
Two Cortex XSIAM modules map directly to this moment:
- Attack Surface Management helps you find what is exposed and close exposure windows fast.
- Threat Intelligence Management helps you treat indicators like a pipeline, not a spreadsheet, so verification becomes repeatable and auditable.
Escalation of Cyber Risk Related to Iran Readiness Checklist
- Use attack surface management to inventory internet facing assets and exposed services.
- Prioritize and close the highest risk exposure windows through patching or mitigation.
- Use threat intelligence management to ingest campaign indicators, enrich them, and merge duplicates.
- Turn out-of-band verification into a case workflow with clear approvals and auditability.
- Run a 30 day lookback to find missed indicators and suspicious activity, then remediate with context.
Shrink Exposure Windows with Attack Surface Management
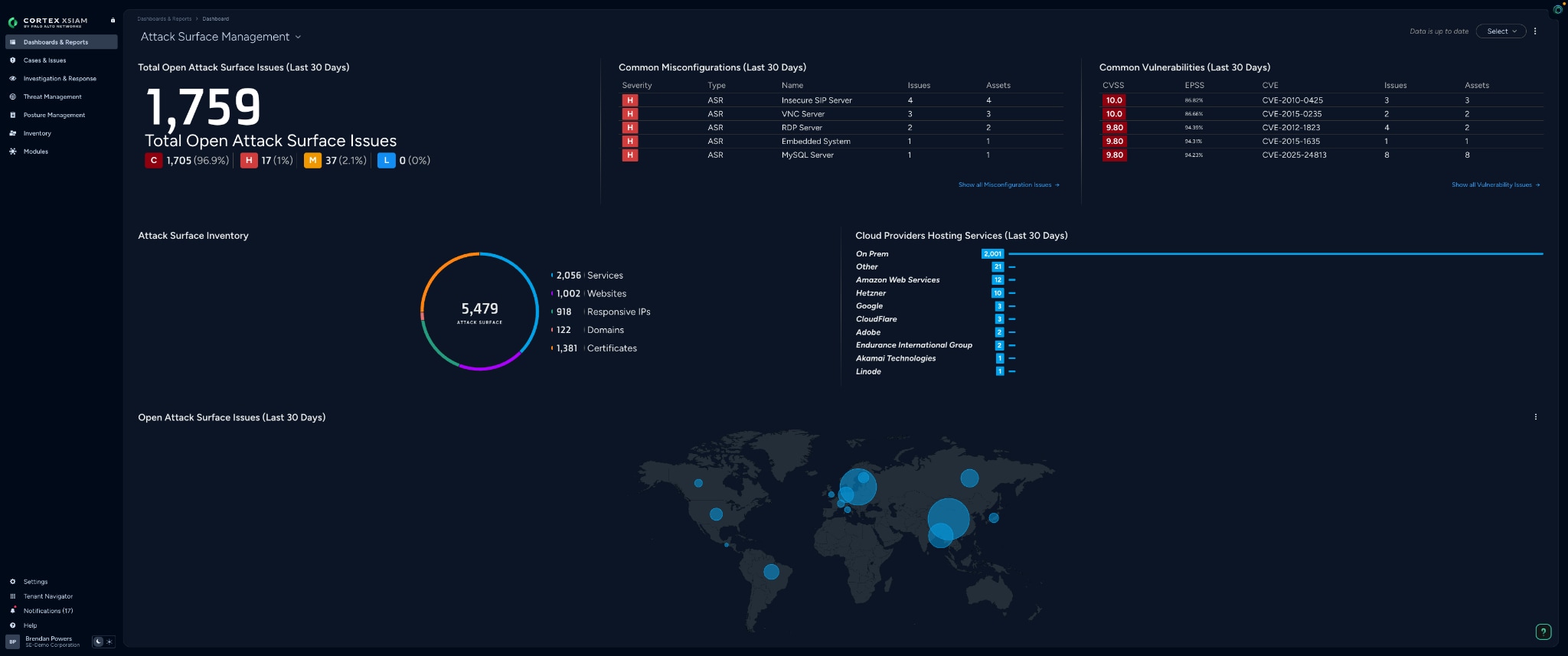
During crisis conditions, attackers start with what they can reach. Internet facing assets, remote access services, and misconfigurations do not wait for your quarterly scan.
Attack surface management gives you continuous outside in visibility into public facing assets, including unknown and unmanaged infrastructure. That matters because most surge risk hides in the seams: the host you forgot, the service that came back online, the cloud edge that no one owns.
What you should do in the first 48 hours is simple:
- Inventory what is internet facing.
- Prioritize the assets that matter most to the campaign.
- Patch where you can, mitigate where you cannot, and verify closure.
You are not trying to perfect the environment. You are trying to close the paths attackers can walk today.
Patch and Harden Fast, with a Second Path for Mitigation
Patch faster is correct advice, but it is not sufficient advice.
In practice, you need two fast ways to respond: patch when a fix is available and safe, or mitigate when patching can’t happen immediately.
Attack surface management supports both by focusing on exposure windows, not vulnerability volume. It prioritizes the exposures that create real, actionable paths right now.
In practice, it usually looks like this:
- Confirm the exposed service and where it lives.
- Decide patch versus mitigate.
- Apply the change.
- Confirm the asset is no longer exposed, and keep monitoring for regression.
Make Out of Band Verification a Workflow with Threat Intelligence Management
Attackers weaponize trust during surges. The most dangerous actions often start with an urgent request: approve access, reset credentials, click the link, share the file, send the money.
Out-of-band verification works best when it’s built into the workflow.. Threat Intelligence Management makes verification easier by automating how indicators are handled. You can ingest indicator sources from feeds and lists, extract indicators from alerts, and enrich and score indicators so analysts get context quickly. You can also manage how indicators are merged when the same indicator shows up from multiple sources, so your team is not debating duplicates instead of making decisions.
That turns verification into a repeatable sequence:
- Is this domain, IP, or hash already known?
- What is the verdict and why?
- Where has it appeared in our environment?
- What action should fire: block, allow list, monitor, or investigate?
Tier 1 analysts aren’t left to improvise anymore. Instead, you are giving them a structured process.
The Missing Step: a 30-day Lookback
Here is the angle most teams skip, and it is the one that pays back the fastest.
Do a 30-day lookback.
In fast moving situations, early signals get logged without context, or dismissed as noise. The lookback is how you catch what you missed when the campaign was still forming.
Run a time boxed retrospective:
- Take the newest indicators from Unit 42 and your internal reporting.
- Search for them across your recent telemetry.
- Correlate matches with exposure context, especially internet facing assets.
- Hunt for quiet precursors, odd logins, unusual SaaS access, strange VPN behavior, and new outbound connections.
You are looking for patterns that were invisible in real time, but obvious in hindsight.
Conclusion
Global conflicts such as Operation Epic Fury do not require a new security philosophy. They require a faster one.
Use attack surface management to shrink exposure windows. Use threat intelligence management to verify signals and act consistently. Then do the lookback so you are not defending the last 24 hours while the attacker is already working on the next 24.
Next step: read the Unit 42 Epic Fury brief, then book a Cortex XSIAM demo to run this checklist against your environment.