1. The AI-Powered Everything Problem
“AI-powered” has become a label of convenience. Vendors attach it to search boxes, dashboards, workflows, scanners and copilots until the phrase stops explaining the product and starts obscuring it.
Enterprise buyers can’t afford that ambiguity. In data security, an AI claim needs to answer harder questions: What does the system understand? Where does the model run? How does it handle sensitive data? Can it classify at enterprise scale without flooding teams with false positives or driving unpredictable cost?
Data classification exposes the difference between AI as a feature label and AI as an engineered capability. A model that misreads sensitive data doesn’t merely produce a bad result. It can misdirect enforcement, mask exposure, trigger noise, and leave the organization with false confidence in its controls.
A stronger question needs to replace the generic AI claim: What should AI-powered data classification look like when it’s designed for scale, accuracy, privacy and trust?
2. Why Data Classification Is a Difficult AI Problem
Data classification has always been difficult because sensitive information rarely announces itself in a consistent format. Some data follows a recognizable pattern, such as a payment card number or national identifier. Much of the data that matters most to an enterprise depends on meaning, context and business intent.
A 16-digit sequence may look like a credit card number without being one. A 10-digit number may resemble a U.S. Social Security number without carrying that meaning. A merger evaluation, board presentation, product roadmap or legal strategy document may contain no regulated fields at all, yet still represent some of the most sensitive data the organization owns.
Rule-based classification struggles at that boundary. Regex can detect patterns, but it can’t reliably infer significance. Keyword matching can find obvious signals, but it misses documents where sensitivity comes from what the content means rather than the terms it contains.
AI becomes useful only when it helps close that gap. Applied poorly, it adds cost and complexity. Applied well, it brings context into classification without turning the system into a black box.
3. From Patterns to Topics: How Context Changes Classification
Modern data classification needs to move beyond asking, Does this file contain a matching string? It needs to ask, What is this file about, and why does that matter?
Topic-based classification makes that shift possible. Instead of relying only on fixed identifiers, an AI-enabled system can recognize categories such as contracts, resumes, payroll records, tax documents, customer data or business strategy based on semantic meaning and contextual cues.
Accuracy depends on more than adding an LLM to the pipeline. Enterprise classification has to work across massive data volumes, sensitive environments, diverse file types and changing business context. It also has to keep costs predictable and avoid sending sensitive content into systems the organization can’t govern.
Topic-based classification offers a useful lens for understanding what AI can contribute to data security. It shows where traditional detection falls short, why model selection matters, and why architecture determines whether AI improves classification or merely makes it harder to control.
4. Precision Tradeoffs: Choosing the Right Model for the Job
No model handles every classification task equally well. Effective data security systems match the model to the workload rather than treating AI as a single layer applied everywhere.
| Approach | Best for | Strengths | Tradeoffs |
|---|---|---|---|
| Embedding-based classifiers | High-volume, repeatable topic classification | Fast, cost-efficient, and operationally scalable | Less effective for highly ambiguous or complex content |
| Smaller self-hosted language models (SLM) | Sensitive environments with stricter control requirements | Greater privacy and deployment flexibility | Slower throughput and more infrastructure overhead |
| Large language models (LLM) | Documents requiring deeper contextual reasoning | Better explainability / rationale | Higher cost and more complex governance considerations |
| Hybrid architectures | Enterprise-scale production environments | Combination of efficiency with deeper reasoning where needed | Need for thoughtful orchestration and tuning |
The right approach depends on the classification task, the sensitivity of the data, and the operational constraints around cost, latency, privacy and control.
In practice, the strongest systems don’t pick one model and force every use case through it. They use lightweight classifiers where speed and scale matter most, and reserve higher-capability models for ambiguous or high-risk content. Accuracy improves when the architecture recognizes the work each model should do.
Precision Depends on Training, Not Just Model Choice
High precision doesn’t come from model size alone. It depends on how well the model has been trained and tuned for the classification task.
In data classification, many topics sit close together. A contract, a legal memo and a procurement document may share similar language. A resume and an employee profile may contain overlapping personal details. A financial forecast may look structurally similar to an ordinary spreadsheet until the system understands the business context.
Well-trained models reduce that ambiguity. They separate closely related topics, create more consistent classification boundaries, and reduce false positives. Poorly trained models produce scattered, overlapping outputs that make classification inconsistent and harder to trust.
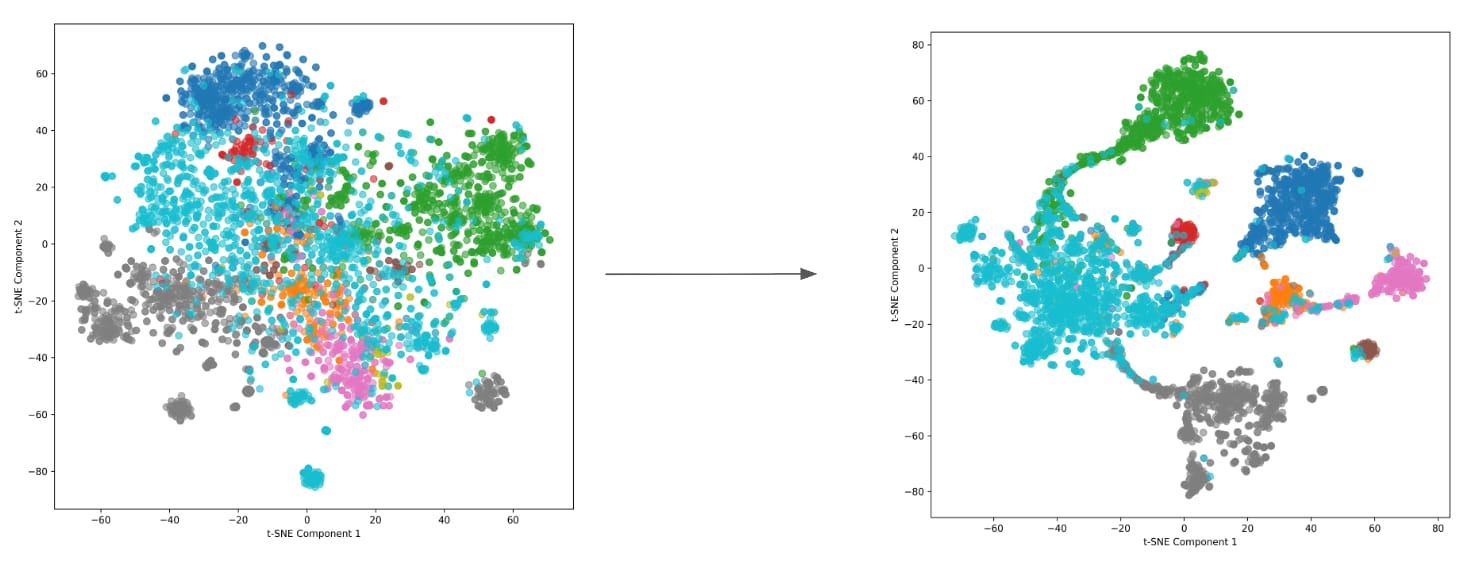
Training turns detection into reliable classification. Without it, the model may recognize similarity. With it, the system can apply meaning consistently enough to support policy, prioritization and enforcement.
The Real Insight
The goal isn’t to choose a single model but to design for the right balance.
In practice:
- Use higher-capability models where context and ambiguity are highest
- Use lightweight models where scale, speed and cost dominate
- Use hybrid architectures when production environments require both efficiency and deeper reasoning
The strongest systems combine these approaches. Lightweight classifiers handle high-volume classification efficiently, while more advanced models analyze ambiguous or high-risk content. A hybrid model strategy gives organizations a practical path to precision without sacrificing scalability, privacy or cost control.
3. Data Privacy and Security: Where the Model Runs Matters
Accuracy and cost matter, but data privacy and security constraints play a key role in architecture decisions.
Where classification happens – be it in vendor-hosted or self-hosted models – determines whether sensitive data leaves the environment and whether regulatory requirements can be met.
Cloud-Hosted Models
Cloud-hosted models can offer immediate scalability and powerful capabilities. They can also help teams deploy AI-enabled classification without managing model infrastructure themselves.
Key considerations include:
- Sensitive data may be sent to an external service
- Data residency and compliance requirements may create constraints
- Governance depends on vendor controls and policies
Self-Hosted Models
Self-hosted models keep data within controlled environments and can better support strict regulatory or internal governance requirements. They also give organizations greater control over how data is handled and processed.
Key considerations include:
- Infrastructure requirements
- Specialized expertise
- Ongoing maintenance
- More operational ownership
For many organizations, especially in regulated industries, choosing one type of model deployment over another isn’t a preference. It’s a requirement.
Architecture decisions are often driven as much by data governance constraints as by performance or cost.
4. Use Case – Cost Tradeoffs: From Per-Call to Total Cost
At scale, classification operates across millions or billions of documents. Small differences in per-call cost can add up quickly, especially when data must be classified, reclassified and evaluated across changing environments.
Cost Across Model Types
| Model Type | Cost Profile | Tradeoffs |
|---|---|---|
| Embedding models | Low cost per classification | Efficient at scale, minimal infrastructure |
| SLM (CPU) | High compute and infrastructure cost | No GPU required, but slower throughput |
| Customer-hostedLLM (GPU) | High compute and infrastructure cost | High performance, but expensive to scale |
| Cloud LLM APIs | Usage-based (per token/request) | Reliable, easy to scale, but cost grows with volume |
Beyond Inference: Hidden Costs
Model pricing matters, but raw inference cost tells only part of the story. Enterprise classification also carries costs tied to the surrounding system, including:
- Data storage and retrieval
- Data transfer (especially across regions)
- Pipeline orchestration
- Model lifecycle management (updates, retraining, evaluation)
Why TCO Matters
When classification runs at enterprise scale, the key question isn’t only what each model call costs. The more important question is what the full classification system costs to operate over time.
Total cost of ownership depends on factors such as:
- Reclassification frequency
- Growth in data volume
- Cost predictability under real workloads
The most effective systems optimize for total cost of ownership, not just raw model pricing. A lower-cost model may become expensive if it requires repeated processing, creates excessive false positives, or can’t scale predictably. A higher-capability model may be worth using when ambiguity or risk justifies the added cost.
In data security, these tradeoffs affect more than budget. False positives create noise. Missed detections create exposure. Cost constraints influence what can realistically be enforced across the environment.
5. Bringing Everything Together: Designing for Real-World Constraints
AI-powered classification isn’t about choosing the most powerful model. It’s about designing systems that work under real-world constraints.
Every deployment must balance:
- Precision and recall
- Cost and scalability
- Privacy and control
Each dimension affects the others. Improving precision may require additional model evaluation or more advanced reasoning. Scaling classification may require more efficient models. Stronger privacy requirements may influence where models run and how data moves through the classification pipeline.
In practice, success comes from designing systems that are measurable, cost-aware, security- and privacy-conscious, and deployable at enterprise scale.
That’s what AI-powered should mean in data security – not a vague product claim but a system designed to classify sensitive data accurately, efficiently, and safely in the environments where enterprises operate.
To learn more about data security, read our recent article, Rethinking Data Security in the AI Era.