You probably noticed that Facebook, along with WhatsApp, Messenger, and Instagram, all experienced outages on Monday. We did too. In fact, it took us less than 30 seconds to immediately diagnose that the outage was with the application vendor itself and identify DNS as the root cause.
But why is this important? While viewing or posting content on Facebook or Instagram may not be business-critical for many organizations, there are tons of other businesses that rely on these apps for their livelihoods. What’s more, it might be Facebook today and another business-critical application tomorrow. As more and more organizations now rely on apps they don’t own for critical business functions, any downtime can have a disastrous impact.
Traditional approaches to issue investigation
Identifying the root cause of service disruption is often time-consuming. The story typically goes like this: A frustrated user submits a trouble ticket causing the IT administrator to spend hours isolating segments to determine whether the problem was first, middle, or last mile.
Starting with the first mile, the admin checks things like end-user device issues including high CPU usage, wireless connectivity issues, or Internet problems at home. And good luck to the user if this is where the problem lies; IT usually can’t help because they don’t have any visibility into the home network.
If the IT administrator confirms the problem isn’t in the first mile, they would then troubleshoot middle mile issues like ISP hops from home to the application.
After ruling out any first and middle-mile problems, the admin would look at last-mile issues like application reachability, DNS, Time to First Byte, Time to Last Byte, packet loss, or jitter to see if there are any application issues.
Based on this common scenario, it’s easy to see why investigating issues impacting user access to applications and other resources takes such a long time to solve.
Use ADEM to find answers in seconds vs. hours
How are we able to do this type of isolation in mere seconds?
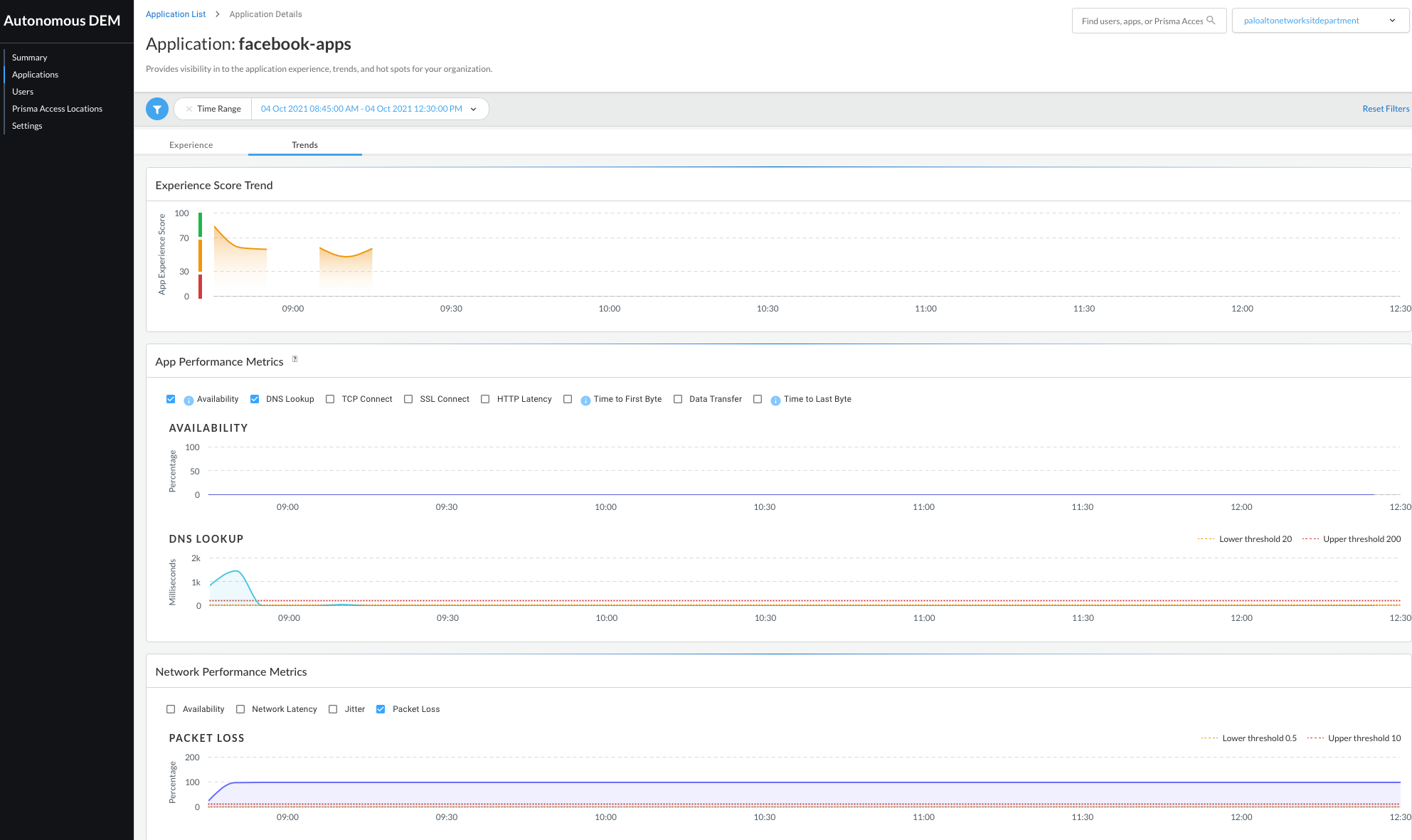
Our Autonomous Digital Experience Management (ADEM) solution continuously monitors and baselines application performance, leveraging multiple critical application and network performance metrics like reachability, DNS lookup, TCP and SSL connect, HTTP latency, jitter, packet loss, and network latency. Because ADEM automates this testing, admins can prioritize their time solving more complex, business-critical issues.
Using a combination of synthetic and real traffic analytics, ADEM baselines the performance of all critical business applications, quickly identifying when performance degradation occurs. By running predictive analytics, ADEM can proactively notify IT administrators of potential issues impacting user experience before they occur - whether that’s a first mile, middle mile, or last-mile issue. And by simultaneously leveraging real traffic monitoring, synthesizing this data into a single user and application experience score, IT admins now have full visibility when outages occur.
Using Palo Alto Networks ADEM, you can easily identify issues impacting business-critical apps faster than you can post your favorite cat videos. For more information on how to use ADEM to solve tough IT challenges, check us out at www.paloaltonetworks.com/sase/adem.