Table of Contents
- How DSPM Is Evolving: Key Trends to Watch
- What Is Data Loss Prevention (DLP) Compliance?
- What Is Data Encryption?
- What Is Cloud Data Loss Prevention (DLP)?
- DSPM Market Size: 2026 Guide
- Top Cloud Data Security Solutions
- What Is Data Risk Assessment?
- What Is a Data Leak?
- Data Security Policies: Why They Matter and What They Contain
- What Is Data Storage?
- What Is Database Security?
- What Is a Data Warehouse?
- What Is Shadow IT?
- What Is an Insider Threat?
- What Is Data Sprawl?
What Is a Data Lake?
5 min. read
Table of Contents
A data lake is a centralized repository that allows the storage of structured and unstructured data at any scale. Unlike traditional databases that require data to fit a specific schema upon entry, data lakes enable organizations to store data as-is, handling large and flexible data without prior structuring or definition.
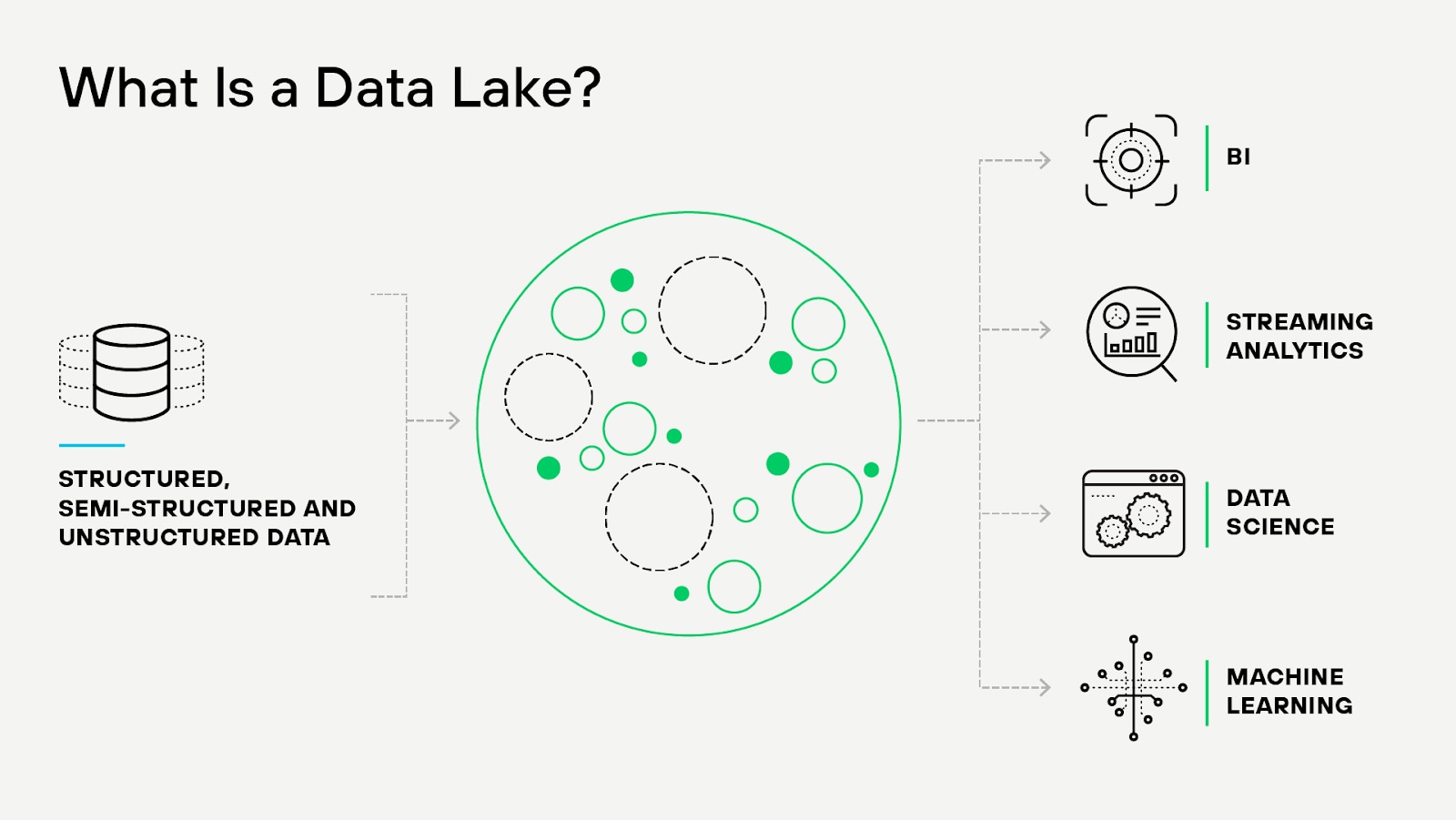
Figure 1: Understanding the nature and use of data lakes
Data Lakes Explained
A data lake is a centralized, large-scale storage repository that holds vast amounts of raw data in its native format, including structured data and unstructured data. It serves as a flexible and scalable data storage solution, accommodating the growing needs of big data analytics and machine learning applications.
In a data lake, data is ingested from multiple sources such as databases, data streams, applications, and IoT devices. This data is stored as-is, without the need for prior transformation or schema definition. As a result, data lakes can handle diverse data types and formats, allowing for faster data ingestion and data storage.
Data lake architecture typically includes three core layers: ingestion, storage, and consumption. The ingestion layer handles data collection from various sources, supporting batch, real-time, and streaming data. The storage layer, often built on distributed file systems like Hadoop HDFS or cloud-based object storage like Amazon S3, stores data in its raw format, ensuring scalability and cost-efficiency. The consumption layer enables users to access, analyze, and process data using tools and applications tailored to their specific needs, such as SQL queries, data visualization, or machine learning algorithms.
Data lakes use metadata and cataloging systems to index and organize data, making it discoverable and accessible for analytics. Data governance, security, and access controls are also essential components of a data lake, ensuring data quality, compliance, and protection against unauthorized access.
By providing a flexible and scalable storage solution, data lakes empower organizations to harness the full potential of their data, enabling advanced analytics, real-time insights, and machine learning-driven innovation.
Data Lake vs. Data Warehouse
Enterprises cannot afford to confuse data lakes with data warehouses. They solve different problems and operate on fundamentally different principles. Each serves a specific purpose within a modern data ecosystem, and misunderstanding the distinction leads to waste, complexity, and risk.
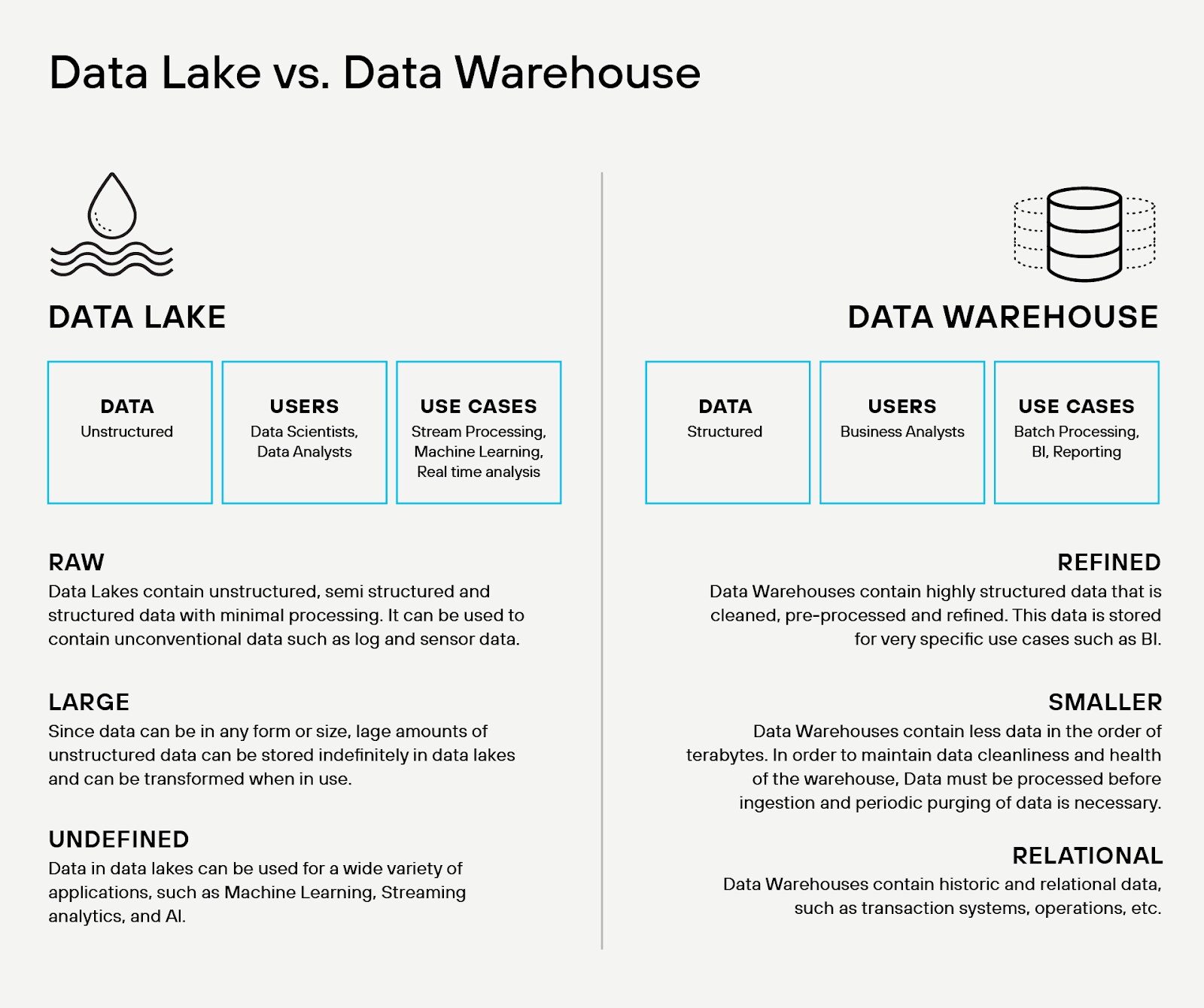
Figure 2: Architectural and operational divergence among the data lake and data warehouse
Schema and Structure
Data warehouses impose structure at write time. The schema must exist before the data enters the system. Analysts, engineers, and database administrators define data models, optimize storage layouts, and validate input against rigid constraints. As a result, warehouses favor structured, relational data from transactional systems and provide high performance for known, repeatable queries.
Data lakes, in contrast, apply schema at read time. They ingest raw data in native formats — structured, semi-structured, and unstructured — without transformation or modeling at the point of ingestion. The lake defers structure until query execution. The late-binding model provides agility but places more burden on downstream consumers to understand, cleanse, and normalize data on access.
Storage and Cost
Data warehouses optimize for compute efficiency. They use columnar storage formats, aggressive compression, indexing, and materialized views to reduce query latency. But this performance comes at a premium. Licensing models often tie cost directly to compute or storage usage, and storage volumes must be curated.
Data lakes rely on low-cost, high-volume object storage. They decouple compute from storage, enabling organizations to retain vast datasets. Cold data can sit dormant without inflating budgets. Compute resources only activate during transformation or analysis, and multiple engines can access the same lake.
Access Patterns and Tooling
Data warehouses shine in environments where business users need curated, trusted data for dashboards and standardized reports. They prioritize fast, repeatable queries over predefined schemas. SQL dominates. BI tools plug in seamlessly.
Data lakes support a broader range of access patterns — machine learning pipelines, ad hoc exploration, anomaly detection, event correlation. Data scientists and engineers often interact with lakes using Python, Spark, or specialized query engines like Trino or Presto. Lakes offer flexibility, but lack the strict governance of warehouses unless layered with metadata catalogs, access policies, and data quality enforcement.
Governance and Lineage
Warehouses enforce strong data governance by design. Since data must conform to the schema at ingestion, it passes through ETL pipelines, where lineage, transformations, and quality checks are tightly controlled. This centralization supports regulatory compliance and auditability.
Data lakes demand additional tooling to reach that same level of control. Raw data flows in with minimal gatekeeping. Metadata catalogs such as Apache Hive, AWS Glue, or Databricks Unity Catalog provide the semantic layer, but governance remains optional unless enforced through data security policy, automation, and architecture.
Use Cases and Integration
The warehouse serves operational reporting, financial analysis, and executive dashboards. The lake captures real-time telemetry, experimental data, and training datasets for AI. The most effective architectures treat the lake as the foundation and the warehouse as a refinement layer for production use cases.
Modern platforms blur the line, offering lakehouse architectures that combine elements of both. But the core distinction remains: warehouses structure data upfront and prioritize precision. Data lakes prioritize flexibility and scale, postponing structure until analysis.
What Are the Benefits of Data Lakes?
The benefits of using data lakes can be significant for many organizations, especially those dealing with large volumes of diverse data. Below is a summary of the key benefits:
- Scalability: They can easily scale to store vast amounts of data, accommodating petabytes or more. This scalability is crucial for organizations that need to handle growing data volumes.
- Flexibility with Data Types: Unlike traditional databases that require specific schemas, data lakes accept structured, semi-structured, and unstructured data. This flexibility allows organizations to store data from various sources without preprocessing.
- Cost-Effectiveness: They often use cost-efficient storage solutions like object storage, making them more affordable for large data sets. The ability to tier storage based on access frequency can also save costs.
- Enhanced Analytics and Insights: By accommodating various data types, they enable more comprehensive data analytics. They can support a wide array of big data processing tools and machine learning algorithms, leading to more nuanced insights and predictions.
- Faster Time to Insights: Storing raw data allows organizations to postpone data structuring until needed, enabling more agile and rapid insight access. Since there’s no need to move the data, calculating analytics is faster.
- Integration and Collaboration: Data lakes can serve as a centralized hub for various data sources, allowing different departments within an organization to access and collaborate on the data. They can be integrated with numerous data processing and analytics tools, enhancing the data’s usability.
- Data Exploration and Experimentation: Data lakes’ ability to store raw data facilitates experimentation and exploration. Data scientists and analysts can play with the data, testing new models and hypotheses without affecting the operational environment.
- Compliance and Security: With proper management and governance, data lakes can support compliance with various regulatory requirements. Storing data in a centralized repository can also make it easier to implement uniform security measures.
- Future-Proofing: The flexibility and scalability means it can adapt to future changes in technology or business requirements, allowing a data lake architecture to evolve with the organization’s needs.
- Disaster Recovery: Many data lakes offer robust disaster recovery options, ensuring no data loss during a failure or catastrophe.
- Support for Real-Time Processing: Some data lakes allow real-time data processing, enabling organizations to react quickly to changing circumstances.
In many industries, data lakes are essential for handling large quantities of raw data that can be transformed and analyzed to gain insights and drive decision-making. They provide a flexible and scalable solution but require careful management to avoid becoming unwieldy or insecure.
Challenges of Using Data Lakes
While data lakes offer a host of advantages, there are several challenges that organizations may encounter. One key issue lies in management. Without careful oversight, data lakes can become unwieldy and hard to navigate. The lack of a predefined structure can give rise to a “data swamp.” In such a scenario, the data is poorly organized, making it difficult for users to locate the information they need and reducing the overall effectiveness of the data lake. Proper governance and quality measures are of paramount importance. Ensuring the correct data cataloging, tagging, and meta-data management protocols exist helps maintain a usable and efficient data lake.
A second significant challenge that can surface when using data lakes involves security. Given their inherent flexibility and complexity, it can be challenging to implement effective security measures in a data lake environment. The wide range of data types and structures housed in a data lake and the different kinds of access that users might require compound this issue.
In an era where data breaches are costly and damaging to a company’s reputation, protecting sensitive data within a data lake is a critical concern. Organizations must implement robust security protocols to continually monitor and safeguard against potential threats. Data security posture management (DSPM) solutions help address these challenges by automatically discovering and classifying data assets within data lakes, providing continuous visibility into data security risks.
Use Cases For Data Lakes
Data lakes are incredibly versatile and can be used in various applications. Here are some everyday use cases:
- Advanced Analytics and Machine Learning: Data lakes are excellent for storing diverse data, including structured and unstructured data, for in-depth analysis and machine learning. For instance, organizations can use a data lake to store and analyze social media, transactional, and IoT device data, among others, to derive insights and train machine learning models.
- Real-Time Analytics: Data lakes can also handle real-time data ingestion and processing, which is critical for applications such as real-time customer recommendation systems, real-time fraud detection, or real-time operational analytics.
- Data Exploration and Data Discovery: Because data stored is in its raw format, it allows data scientists and analysts to explore and experiment with different modeling techniques. They can quickly access vast amounts of raw data, enabling more freedom to discover new insights or trends.
- Big Data Processing: The ability to store large amounts of raw data in data lakes makes it a natural fit for big data processing. With the help of tools like Hadoop and Spark, organizations can process and analyze big data within itself.
- Data Warehousing: While traditional data warehouses remain in use, they can also serve as modern data warehousing solutions, acting as a cost-effective solution for storing historical data and is often used with traditional data warehouses.
- Customer 360 View: Businesses can integrate business data from various sources into a data lake to create a comprehensive view of their customers. This enables them to provide personalized experiences, improve customer service, and optimize marketing efforts.
- Regulatory Compliance and Reporting: They can store large volumes of historical data, which is helpful for regulatory compliance and reporting. In regulated industries, businesses can use data lakes to store data for an extended period and generate reports for regulatory bodies.
- Data Consolidation: For organizations with disparate data sources, data lakes can serve as a central repository for all data, eliminating data silos.
Remember, the use cases can vary depending on an organization’s specific needs. The key is to clearly understand the business requirements and goals before designing and implementing a data lake solution.
Data Lake FAQs
In the context of cloud security, a data lake presents unique challenges and opportunities. The vast amounts of diverse, raw data stored in a data lake require robust security measures, access controls, and encryption to protect sensitive information. Additionally, data lakes must comply with relevant data protection regulations, such as GDPR and CCPA. Implementing proper data governance practices and utilizing advanced security tools helps ensure data security within data lakes while maintaining flexibility and scalability.
Centralized storage in the cloud refers to a single, unified storage location for data from various sources, services, and applications. It enables efficient data organization, management, and access, eliminating data silos and promoting collaboration across an organization. Cloud-based centralized storage solutions, such as data lakes or cloud object storage, provide scalability, cost-efficiency, and simplified data management, enhancing data availability and security.
Structured data is data organized in a predefined, consistent format, making it easily searchable and analyzable. It often resides in relational databases or spreadsheets and follows a schema with defined data types, relationships, and constraints. In the cloud, structured data can be stored in various services, such as relational database management systems (RDBMS), data warehouses, or data lakes, depending on an organization's requirements and objectives.
Unstructured data refers to data without a specific format or organization, making it more challenging to analyze and process. Examples include text documents, images, videos, and sensor data from IoT devices. In the cloud, unstructured data can be stored in data lakes, object storage, or NoSQL databases, which are designed to handle diverse data types and formats without the need for predefined schemas.
Data management in the cloud encompasses the strategies, processes, and tools used to organize, store, protect, and maintain data across cloud environments. It ensures data availability, reliability, and security while optimizing storage and resource utilization. Cloud data management includes data ingestion, data quality management, data governance, access controls, data backup and recovery, and data lifecycle management.
Big data analytics is the process of examining vast, diverse datasets to uncover hidden patterns, trends, correlations, and insights. In the cloud, big data analytics leverages distributed computing resources, parallel processing, and advanced analytics tools, such as Hadoop, Spark, and machine learning algorithms, to process and analyze large volumes of data more efficiently and cost-effectively than traditional methods.
Machine learning is a subset of artificial intelligence (AI) that involves training algorithms to learn from data, identify patterns, and make predictions or decisions without explicit programming. In the cloud, machine learning platforms and services provide scalable, on-demand computing resources, pre-built models, and advanced tools to develop, train, and deploy machine learning models with greater efficiency and lower costs.
Data ingestion in the cloud is the process of collecting, importing, and transforming data from various sources into a centralized storage system, such as a data lake or data warehouse. It supports batch, real-time, and streaming data, enabling organizations to process and analyze data more efficiently. Cloud-based data ingestion tools, such as Apache Kafka, Amazon Kinesis, and Azure Event Hubs, facilitate scalable and reliable data ingestion across multiple sources and destinations.
Data quality in the cloud refers to the accuracy, completeness, and reliability of data stored and processed across cloud environments. Ensuring data quality involves validating, cleansing, and enriching data to eliminate errors, inconsistencies, and duplicate information. High data quality is essential for making informed decisions, improving operational efficiency, and reducing the risk of costly mistakes.
Data governance in the cloud is the set of practices, policies, and processes that ensure the effective management, security, and quality of data across cloud platforms and services. It involves defining data policies, implementing access controls, monitoring compliance, and maintaining data accuracy and consistency. Robust data governance in the cloud helps protect sensitive data, comply with regulations, and ensure data integrity, enabling organizations to make informed decisions and optimize resources.
A data catalog in the cloud is a centralized metadata repository that indexes, organizes, and describes data stored across various cloud services and platforms. It enables users to discover and understand available data assets, their relationships, and their usage. Cloud-based data catalogs utilize advanced search capabilities, data profiling, and automated metadata extraction to improve data discoverability, promote collaboration, and support data governance initiatives.
Data architecture in the cloud refers to the design and structure of data storage, processing, and management systems across cloud platforms and services. It includes data organization, data models, data flow, and integration strategies, ensuring data consistency, security, and compliance. Cloud-based data architecture leverages distributed storage solutions, scalable computing resources, and advanced data processing tools to accommodate diverse data types and formats while optimizing performance and cost-efficiency.
Data integration in the cloud involves consolidating data from various sources, platforms, and services to create a unified and consistent view of information. This process includes extracting, transforming, and loading (ETL) data into a centralized repository or data warehouse, enabling efficient data analysis and reporting. Cloud-based data integration requires robust data governance practices and integration tools, such as Apache NiFi, Talend, and Informatica, to ensure data accuracy, consistency, and security across multiple cloud environments.
Data exploration in the cloud refers to the process of examining, analyzing, and visualizing data to discover patterns, trends, and insights. It involves using cloud-based data analytics and visualization tools, such as Tableau, Power BI, and Amazon QuickSight, to interact with data stored in data lakes, data warehouses, or other cloud storage solutions.