Table of Contents
- What Is Cybersecurity Compliance?
- What Is NIST?
- What Is Personal Data?
- An Overview of FedRAMP and Why You Should Care About It
- What Is Data Compliance?
- What Is the California Consumer Privacy Act (CCPA)?
-
What Is Healthcare Cybersecurity?
- Why Is Cybersecurity Important to Healthcare
- Elements of Healthcare Cybersecurity
- HIPAA Security Rule
- Healthcare Data Breaches
- Healthcare Business Continuity
- Protected Healthcare Information
- Key Challenges in Healthcare Cybersecurity
- Healthcare Cybersecurity Strategies and Solutions
- The Future of Healthcare Cybersecurity
- Healthcare Cybersecurity FAQs
- What Is GDPR Compliance?
-
What Is HIPAA?
- Is Your Organization HIPAA Compliant?
- Understanding HIPAA
- What Is Protected Health Information (PHI)?
- HIPAA: Breach Notification
- HIPAA Privacy Rule: The Standard of Minimum Necessary
- The Security Rule: Safeguarding Electronic Protected Health Information
- OCR Audit Protocol
- HIPAA for Big Tech and Startups
- HIPAA Compliance Tips for DevOps and AppSec Practitioners
- HIPAA FAQs
- What Is SOC 2 Compliance?
-
What Is Healthcare Business Continuity?
- Why Is Business Continuity Important to Healthcare?
- Potential Disruptions to Healthcare Organizations’ Continuity
- The Growing Threat of Ransomware in Healthcare
- Why Healthcare Is a Prime Target for Cyberattacks
- How Healthcare Business Continuity Directly Impacts Lives
- Costs of Downtime in the Healthcare Sector
- How to Ensure Business Continuity in Healthcare
- Benefits of Business Continuity Planning
- Healthcare Business Continuity FAQs
- What Are HIPAA Security Rules?
- What Is Protected Health Information (PHI)?
-
What Is Data Governance?
- Data Governance Explained
- Why Data Governance Matters
- The Benefits of Data Governance
- Enterprise Data Governance Challenges
- Cloud Data Governance Challenges
- Data Governance Strategy
- Building a Strong Data Governance Framework
- Data Governance Best Practices: Tips and Strategies
- Securing Data Access: The Importance of Data Access Governance
- Unlock the Full Potential of Your Data with Comprehensive Data Governance Capabilities
- Data Governance FAQs
-
What is the Difference between FISMA and FedRAMP?
-
Simplified Healthcare Compliance and Risk Management with Prisma Cloud
- What Is Data Privacy?
-
How to Maintain AWS Compliance
- What Is Data Privacy Compliance?
- How The Next-Generation Security Platform Contributes to GDPR Compliance
- What Is PCI DSS?
- What Is PII?
What Is Sensitive Data?
5 min. read
Table of Contents
Sensitive data, also known as sensitive personal data or sensitive personally identifiable information (SPII), refers to information that, if disclosed, misused, or accessed without authorization, could result in harm, discrimination, or adverse consequences for the individual to whom the data pertains.
While definitions of sensitive data vary across jurisdictions, industries, and data protection regulations, organizations must comply with relevant laws and guidelines to ensure the protection of sensitive data and maintain individuals' privacy. Noncompliance with data protection regulations and laws can result in severe legal repercussions for organizations, including substantial fines, penalties, reputational damage, loss of customer trust, and potential litigation.
Sensitive Data Explained
Protecting sensitive data represents one of the top challenges for modern enterprises. The cornerstone of business in the digital age, sensitive data can expose a company to enormous risks, including financial loss, legal action, and reputational damage.
Sensitive data is any kind of information protected against unwarranted disclosure. It involves a wide range of categories, including personal data, financial information, proprietary details, health records, or trade secrets. Inadequately protected sensitive data can lead to a severe data breach that could harm an individual and, as a result, devastate an organization.
Personal Data Vs. Sensitive Data
Not all sensitive data is personal data, but all personal data is sensitive. Personal data is any information that can identify an individual, including their name, email address, phone number, birth date, government-issued identification, and digital identifiers such as IP address or cookie ID.
Sensitive data includes personal data but has a wider scope, which encompasses data that if disclosed could cause harm or adverse consequences for the individual concerned. Common examples of sensitive data include financial account information, health records, and trade union memberships. Less intangible examples, often resulting in discrimination, include political opinions, religious or philosophical beliefs, genetic information, sexual history or orientation, and racial or ethnic origin.

Figure 1: Our researchers found no differences between the distribution of sensitive data types in structured and unstructured managed services.
Data Security and Data Breaches
As more organizations rely on digital processes and online transactions, the security of sensitive data has become increasingly important. Data security involves a series of protective digital privacy measures applied to prevent theft or unauthorized access to computers, databases, websites, and cloud applications. If these measures fail or are bypassed, it can result in a data breach — an incident where unauthorized parties access and potentially misuse sensitive data.
Data Classification and Data Privacy
Data classification is a vital aspect of data privacy and protection. It involves categorizing data based on its level of sensitivity, value, and criticality. By classifying data, organizations can apply appropriate protective measures and controls to prevent unauthorized access and maintain data privacy.
Understanding the Types of Sensitive Data
When it comes to sensitive data protection, it's important to realize that data can fall to different categories, each with its unique implications for privacy and security. Below, we delve into some of the most common types of sensitive data and the regulations associated with their protection.
Brief Reference of Common Sensitive Data
|
|
Financial Information
Financial information includes data related to an individual's or an organization's financial status. It encompasses bank account numbers, debit or credit card details, transaction data, and other financial statements. Given its nature, the unauthorized exposure of financial data can lead to severe consequences like fraud or identity theft.
Protected Health Information (PHI)
Protected health information refers to any information about the provision of healthcare, health status, or payment for healthcare that can be linked together to identify a specific individual. This could include medical records, lab results, health insurance details, and billing information. If this data is compromised, it can result in significant privacy violations and potential harm to the individual's personal and professional life.
Access Credentials
Access credentials generally include usernames, passwords, PINs, and biometric data. Any credentials used to grant or deny access to specific data, systems, or physical locations. When stolen or misused, these can provide criminals with unauthorized access to critical systems and sensitive data.
Various data protection regulations like GDPR and California Consumer Privacy Act (CCPA) cover access credentials based on their usage and context. Best practices to secure them rely on stringent access management, encryption, and regular rotation.
Trade, Proprietary, and Government Information
Trade secrets, proprietary information, and classified government data represent another category of sensitive data. Unauthorized disclosure of this type of data holds the potential for severe consequences, including the erosion of competitive advantage, entanglement in legal disputes, and the emergence of national security threats.
Several regulations cover information that falls to this category, though they vary widely based on the industry and country. Examples include the United States’ Defend Trade Secrets Act (DTSA) and the European Union’s Trade Secrets Directive.
Personal Identifiable Information (PII)
Personal Identifiable Information refers to any data that can be used to identify a specific individual. Names, addresses, phone numbers, social security numbers, and digital identifiers like IP addresses or cookie IDs fall into this category. The misuse of this data can lead to identity theft, fraud, or other forms of cybercrime.
The types of sensitive data your organization handles will shape your data protection strategies and dictate the regulations with which you need to comply.
Navigating the Landscape of Data Privacy Regulations
Data privacy regulations are legal frameworks designed to safeguard individuals' personal information from unauthorized access, misuse, and breach. They set forth stringent standards for the collection, storage, processing, and sharing of personal data, placing the burden of responsibility squarely on organizations that handle such sensitive data. Here, we explore some of the most pivotal regulations influencing global data privacy practices.
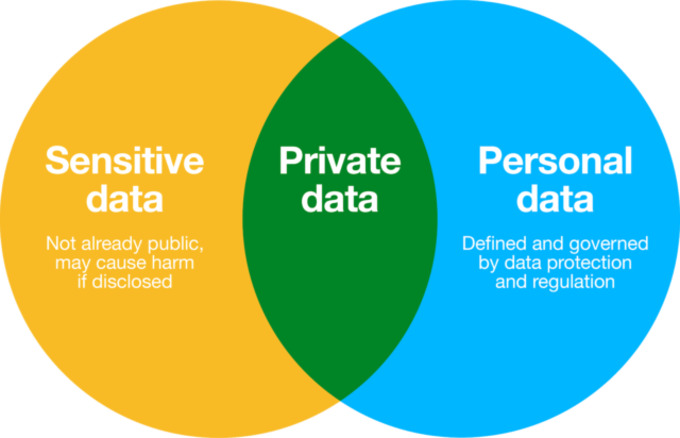
Figure 2: Understanding the overlap of sensitive and personal data.
General Data Protection Regulation (GDPR)
A landmark in data privacy regulation, the GDPR became effective in 2018 and impacts any entity, irrespective of geographic location, processing the personal data of individuals within the European Union. GDPR enforces strict principles on personal data handling, from its collection to its eventual erasure, prioritizing transparency, data minimization, and the necessity for explicit consent. Noncompliance can lead to substantial fines, up to 4% of the company's global annual turnover or €20 million, whichever is higher.
California Consumer Privacy Act (CCPA)
The CCPA represents a significant stride in U.S. data privacy legislation. Enacted in 2018, the law grants California residents enhanced control over their personal information, entitling them to know what data organizations collect about them, why it’s being collected, and with whom it's shared. Additionally, it provides consumers with the right to opt out of the sale of their personal data and the right to nondiscrimination for exercising their CCPA rights.
New York Stop Hacks and Improve Electronic Data Security Act (NY SHIELD)
NY SHIELD, effective from March 2020, expands the obligations of businesses handling New York residents’ private data, regardless of whether the organization is based in New York. NY SHIELD broadens the definition of private information and requires businesses to implement risk assessments, workforce training, and incident response planning among other provisions of their data security program.
Health Insurance Portability and Accountability Act (HIPAA)
HIPAA is a U.S. federal law that sets national standards for the protection of sensitive patient health information. It applies to health plans, healthcare providers, healthcare clearinghouses, and any of their business associates. HIPAA's Privacy Rule requires the safeguarding of protected health information (PHI), while its Security Rule mandates physical, technical, and administrative safeguards for electronic PHI.
Payment Card Industry Data Security Standard (PCI DSS)
PCI DSS refers to the information security standard created by major credit card companies for any organization that handles their branded credit cards. As an industry-accepted standard, PCI DSS serves as a baseline of technical and operational requirements businesses are expected to implement to protect account data. Noncompliance can lead to fines, increased transaction fees, and even the loss of the ability to process cards.
Other Relevant Regulations
Additional global data privacy laws, such as Brazil's LGPD (General Data Protection Law), Canada's PIPEDA (Personal Information Protection and Electronic Documents Act), and Australia's Privacy Act, continue to shape the data privacy landscape. Organizations operating in multiple jurisdictions should ensure they understand and comply with these varying requirements.
Data compliance isn't an option but a critical business imperative. As regulatory frameworks continue to evolve, organizations should regularly evaluate and enhance their data privacy and security measures to ensure they meet or exceed the prescribed standards.
Sensitive Data Protection: Best Practices
Protecting sensitive data requires a comprehensive approach. Organizations can begin with the following strategies:
- Implement access controls aligning with the principle of least privilege (PoLP) to ensure that employees have access only to data needed to perform their duties.
- Encrypt sensitive data while at rest and while in transit protects it from unauthorized access or interception.
- Continually monitor and audit data access and usage to detect and respond to potential breaches promptly.
- Regularly train employees on data security best practices and the importance of handling sensitive data responsibly.
- Use techniques like data masking and pseudonymization to obscure sensitive data, especially in nonproduction environments.
- Deploy data security posture management (DSPM) to dynamically track and secure sensitive data throughout its lifecycle, providing comprehensive visibility into data location, access patterns, and security measures across cloud environments.
Sensitive Data FAQs
Data masking is a security technique that replaces sensitive data with fictional or obfuscated information, ensuring that the underlying data remains inaccessible to unauthorized users. Techniques for data masking techniques include substitution, shuffling, number and date variance, and encryption with a reversible algorithm.
Pseudonymization is a data protection technique in which personally identifiable information (PII) is replaced with artificial identifiers or pseudonyms. This process retains a link between the original data and the pseudonym, allowing for data reidentification when necessary. Pseudonymization provides a layer of security, protecting sensitive data from unauthorized access while maintaining its usability for analysis and processing.
Although not as secure as anonymization, pseudonymization complies with data privacy regulations like GDPR, enabling organizations to work with datasets without directly exposing individuals' personal information.
Data anonymization is the irreversible process of removing personally identifiable information (PII) from a dataset, ensuring that individuals can’t be identified. Anonymization techniques include aggregation, generalization, and data perturbation. By anonymizing data, organizations can protect sensitive information while still utilizing the data for analysis, research, and statistical purposes.
Anonymized data is considered compliant with data privacy regulations, as the risk of exposing personal information is minimized, and reidentification is highly unlikely.
Data minimization is a data protection principle that requires organizations to limit the collection, processing, and storage of personal data to the minimum necessary for achieving the intended purpose. Beyond collecting only essential data, data minimization techniques include anonymizing or pseudonymizing data, and establishing strict retention policies.
Data leakage refers to the unauthorized transfer or exposure of sensitive data from within an organization to external parties or unauthorized individuals. Human error, malicious insider activities, system vulnerabilities, and inadequate security measures can all result in data leakage.
Data loss prevention (DLP) is a set of strategies, policies, and tools designed to detect and prevent the unauthorized disclosure, transfer, or destruction of sensitive data. DLP solutions monitor data in motion, at rest, and in use, identifying potential security incidents and enforcing protective measures. By leveraging techniques like content inspection, data classification, and policy enforcement, DLP systems help safeguard sensitive information against loss, theft, and accidental disclosure.
Sensitive information, when stored, requires advanced security measures to protect it from unauthorized access. Effective measures include encryption at rest, access controls, data classification, and regular security audits.
Proper data storage practices for sensitive information also involve segregating it from less sensitive data, implementing multifactor authentication, and monitoring for anomalies or potential breaches.
Data retention refers to the practice of preserving and storing data for a specified period to meet legal, regulatory, or business requirements. Organizations establish data retention policies to determine the duration and conditions under which data is retained. Policies should ensure compliance with relevant laws and reduce the risk of data breaches. Specifications to document in retention policies might include data classification, storage locations, and data disposal methods.
At the end of the retention period, data should be securely deleted or anonymized in keeping with best practices.
Data destruction is the process of securely and permanently deleting or rendering data unreadable. Organizations should establish data destruction policies to ensure sensitive information is disposed of in compliance with data protection regulations.
The right to be forgotten, also known as the right to erasure, is a data subject right under the GDPR that allows individuals to request the removal of their personal data from an organization's records. This right applies in specific circumstances, such as when data is no longer necessary for its original purpose, consent is withdrawn, or processing is based on legitimate and objectionable interests. Organizations must comply with valid erasure requests within a reasonable timeframe, ensuring that data is securely deleted or anonymized in accordance with data destruction best practices.
Data subject rights refer to the legal entitlements that individuals have regarding the collection, processing, and storage of their personal data. These rights, often established by data protection regulations like GDPR and CCPA, empower individuals to exercise control over their personal information.
Access control and data access control are related concepts, but they have distinct differences. Access control is a broader security practice that manages permissions for accessing resources, including systems, applications, and networks. It employs mechanisms like authentication, authorization, role-based access, and multifactor authentication.
Data access control focuses on regulating access to data based on user roles, responsibilities, and security requirements. Techniques used in data access control include encryption, data classification, and data masking, ensuring that sensitive information is only accessible to authorized individuals.
Tokenization is a data security technique that replaces sensitive data, such as credit card numbers or personally identifiable information, with nonsensitive tokens. These tokens retain the original data's format but don’t carry intrinsic value or meaning. The original sensitive data is stored securely in a separate token vault, accessible only through token-to-data mapping.
A data breach notification is a legal requirement for organizations to inform affected individuals and relevant authorities of a security incident involving unauthorized access, disclosure, or loss of personal data. Data breach notifications must be timely, typically within 72 hours of becoming aware of the breach, and include details about the incident, potential consequences, and measures taken to mitigate the impact.
Privacy by design is a proactive approach to embedding data protection principles and privacy considerations into the development and operation of systems, applications, and processes. Common principles include minimizing data collection, limiting data retention, ensuring data security, and promoting transparency.
Privacy by default is a data protection principle that requires systems and applications to be configured with the highest privacy settings by default, without requiring user intervention. This practice aims to ensure that personal data is only collected, processed, and shared when absolutely necessary and with explicit consent from the data subject.
Privacy by default also mandates that access to sensitive data is restricted by default, with permissions granted on a need-to-know basis.
Data inventory — a comprehensive record of data assets, including data types, locations, and details involved in their collection, storage, and processing — helps organizations understand the flow of data within their systems to identify security risks. They play a helpful role in managing data access controls and implementing effective data governance practices.
Data mapping is the process of creating visual representations of the relationships and flows of data within an organization's systems and processes. It helps organizations understand how data is collected, stored, processed, and shared across different systems, applications, and third parties. Data mapping is essential for complying with data protection regulations, as it enables organizations to identify risks, maintain data accuracy, and respond to data subject rights requests.
Sensitive legal information typically involves data that, if disclosed without authorization, could cause harm or adverse consequences to the individual or organization concerned. Examples of sensitive legal information include criminal records, litigation records, settlement agreements, privileged communications, legal advice, intellectual property records, and contractual agreements.