What Is RLHF? Reinforcement Learning from Human Feedback

RLHF (reinforcement learning from human feedback) trains models to follow human preferences by using human judgments as signals for reward. This makes outputs more consistent with expectations, but it also creates new risks if feedback is poisoned or manipulated.
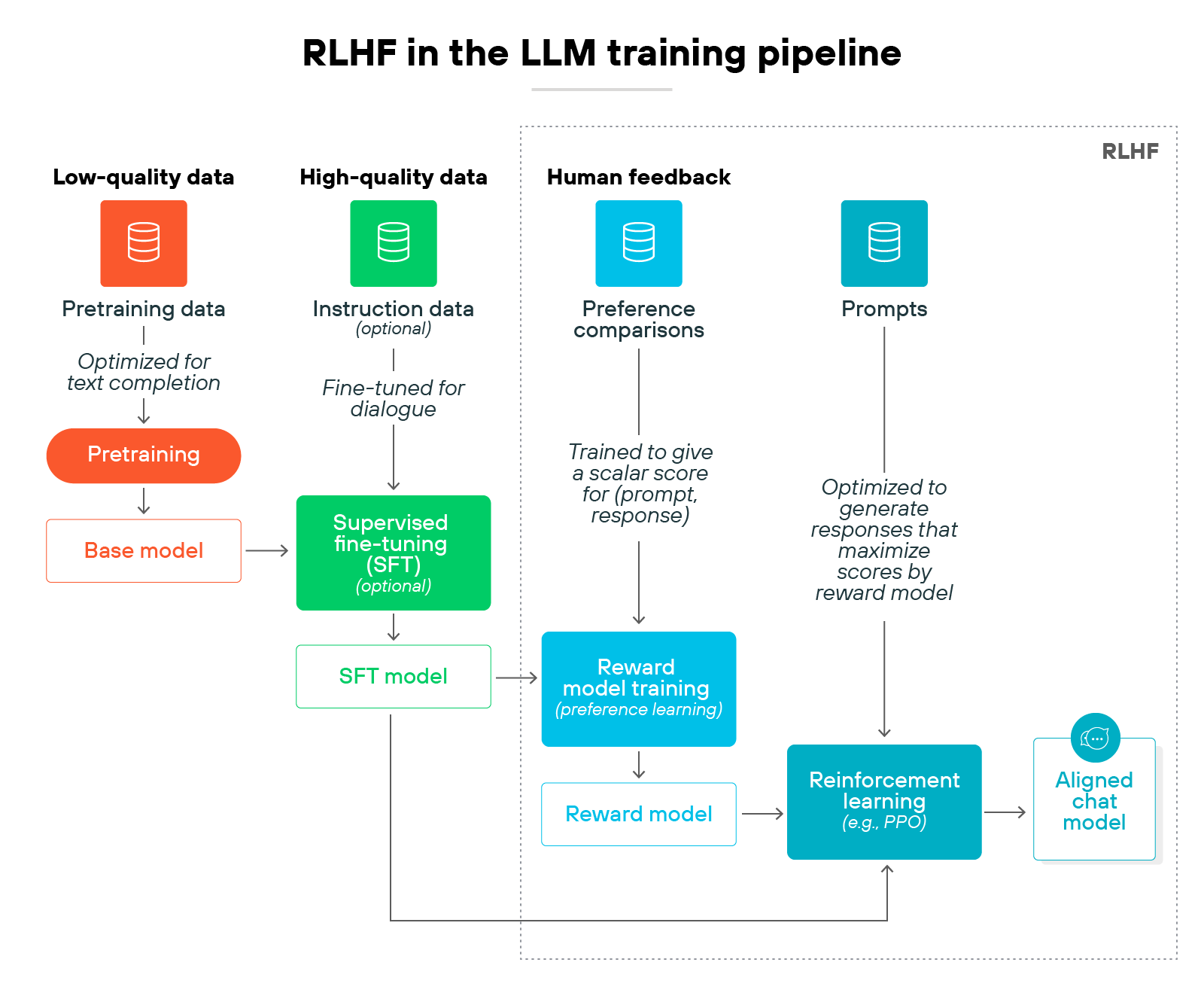
How does RLHF work?

Reinforcement learning from human feedback (RLHF) takes a pretrained model and aligns it more closely with human expectations.
It does this through a multi-step process:
- People judge outputs
- Those judgments train a reward model
- Reinforcement learning then fine-tunes the base model using that signal
Here's how it works in practice.
Step 1: Begin with a pretrained model
The process starts with a large language model (LLM) trained on vast datasets using next-token prediction. This model serves as the base policy.
It generates fluent outputs but is not yet aligned with what humans consider helpful or safe.
Step 2: Generate outputs for prompts
The base model is given a set of prompts. It produces multiple candidate responses for each one.
 containing a neural network graphic. From this, an arrow leads to a text block labeled generated text with placeholder lorem ipsum text. An arrow then connects to a box labeled human preference ranking that includes an icon of three user figures. To the right, arrows branch out to five stacked colored circles arranged vertically in green, light green, yellow, orange, and red, labeled preference rankings. An arrow from these circles points upward to a blue box labeled reward model, which contains a bar chart graphic. A final arrow loops back from the reward model box to the text block, with the label train on {sample, reward} pairs. At the bottom of the diagram, a caption reads: 'Human-scored outputs are converted into ranked preferences to train a reward model for reinforcement learning.'")
These outputs create the material that evaluators will compare.
Step 3: Gather human preference data
Human evaluators rank the candidate responses. Ranking provides clearer signals than rating each response alone.

The result is a dataset of comparisons that show which outputs are more aligned with human expectations.
Step 4: Train a reward model
The preference dataset is used to train a reward model. This model predicts a numerical reward score for a given response.
In other words: It acts as a stand-in for human judgment.
Step 5: Fine-tune the policy with reinforcement learning
The base model is fine-tuned using reinforcement learning–most often proximal policy optimization (PPO).
The goal is to maximize the scores from the reward model. This step shifts the model toward producing outputs people prefer.
Step 6: Add safeguards against drift

Step 7: Evaluate and iterate
The process doesn’t stop after one round.
Models are tested, outputs are re-ranked, and the reward model can be updated. Iteration allows continuous refinement and helps uncover weaknesses.
To sum it up: RLHF builds on pretrained models by layering human judgment into training. Each step moves the model closer to outputs that are safe, useful, and appropriate for intended use.
Why is RLHF central to today's AI discussions?
RLHF is at the center of AI discussions because it directly shapes how models behave in practice.
It's not just a technical method. It's the main process that ties powerful LLMs to human expectations and social values.
Here's why that matters.
RLHF can be thought of as the method that connects a model's raw capabilities with the behaviors people expect.
The thing about large language models is that they're powerful–but unpredictable. RLHF helps nudge LLMs toward responses that people judge as safe, useful, or trustworthy. That's why AI researchers point to RLHF as one of the few workable tools for making models practical at scale.
But the process depends on preference data. Preference data is the rankings people give when comparing different outputs. For example, evaluators might mark one response as clearer or safer than another. Which means the values and perspectives of evaluators shape the results.
' with a brain icon and a warning triangle. Below, a connected box labeled 'Validate (Biased preference data)' contains a head icon with a warning triangle. Arrows loop between the train and validate boxes, and an arrow extends right from the train box to a dark circle labeled 'Test' with a checklist icon. A dotted line also connects the train box directly to the test circle.")
So bias is always present. Sometimes that bias reflects narrow cultural assumptions. Other times it misses the diversity of views needed for global use. And that has raised concerns about whether RLHF can fairly represent different communities.
The impact extends beyond research labs.
How RLHF is applied influences whether AI assistants refuse dangerous instructions, how they answer sensitive questions, and how reliable they seem to end users.
In short: It determines how much trust people place in AI systems and whose values those systems reflect.
What role does RLHF play in large language models?
Large language models are first trained on massive datasets. This pretraining gives them broad knowledge of language patterns. But it doesn't guarantee that their outputs are useful, safe, or aligned with human goals.
RLHF is the technique that bridges this gap.
It takes a pretrained model and tunes it to follow instructions in ways that feel natural and helpful. Without this step, the raw model might generate text that is technically correct but irrelevant, incoherent, or even unsafe.
In other words:
RLHF transforms a general-purpose system into one that can respond to prompts in a way people actually want.
Why is this needed?
Scale. Modern LLMs have billions of parameters and can generate endless possibilities. Rule-based filtering alone cannot capture the nuances of human preference. RLHF introduces a human-guided reward signal, making the model's outputs more consistent with real-world expectations.
Another reason is safety. Pretrained models can reproduce harmful or biased content present in their training data. Human feedback helps steer outputs away from these risks, though the process is not perfect. Biases in judgments can still carry through.
Finally, RLHF makes LLMs more usable. It reduces the burden on users to constantly reframe or correct prompts. Instead, the model learns to provide responses that are direct, structured, and more contextually appropriate.
Basically, RLHF is what enables large language models to function as interactive systems rather than static text generators. It's the method that makes them practical, adaptable, and in step with human expectations.
Though not without ongoing challenges.
What are the limitations of RLHF?

Reinforcement learning from human feedback is powerful, but not perfect.
Researchers have pointed out clear limitations in how it scales, how reliable the feedback really is, and how trade-offs are managed between usefulness and safety.
These challenges shape ongoing debates about whether RLHF can remain the default approach for aligning large models.
Let's look more closely at three of the biggest concerns.
Scalability
RLHF depends heavily on human feedback. That makes it resource-intensive.
For large models, gathering enough quality feedback is slow and costly. Scaling this process across billions of parameters introduces practical limits.
Inconsistent feedback
Human feedback is not always consistent.
Annotators may disagree on what constitutes an appropriate response. Even the same person can vary in judgment over time.
This inconsistency creates noise in the training process. Which means: Models may internalize preferences that are unstable or poorly defined.
“Helpful vs. harmless” trade-offs
RLHF often balances two competing goals. Models should be helpful to the user but also avoid harmful or unsafe outputs.
These goals sometimes conflict.
A system optimized for helpfulness may overshare sensitive information. One optimized for harmlessness may refuse useful but safe answers.
The trade-off remains unresolved.
What is the difference between RLHF and reinforcement learning?
Reinforcement learning (RL) is a machine learning method where an agent learns by interacting with an environment. It tries actions, receives rewards or penalties, and updates its strategy. Over time, it improves by maximizing long-term reward.
' shows a loop between an agent and an environment. On the left, the agent is depicted inside a box containing two components: a dark blue square labeled 'Policy' with an arrow pointing right to 'Action,' and a teal square labeled 'Reinforcement learning algorithm' with a brain icon. A downward arrow labeled 'Policy update' connects the policy to the reinforcement learning algorithm. On the right, a large gray rectangle labeled 'Environment' contains icons of a computer screen, database, and people. A right-facing arrow labeled 'Action' connects the policy to the environment. A left-facing arrow labeled 'Reward' connects the environment back to the reinforcement learning algorithm. A second left-facing arrow labeled 'Observation' connects the environment back to the policy.")
RLHF builds on this foundation. Instead of using a fixed reward signal from the environment, it uses human feedback to shape the reward model. Essentially: People provide judgments on model outputs. These judgments train a reward model, which then guides the reinforcement learning process.
' is divided into three sections: pretraining, human feedback, and fine-tuning. On the left, the pretraining section shows a purple cylinder labeled 'Pretraining data' feeding into an icon of a lightbulb labeled 'Self-supervised learning,' which connects to a light blue box labeled 'Base LLM (pretrained).' An arrow from the base LLM flows downward into a dark blue circle labeled 'Supervised fine-tuning,' which then points right into a gray box labeled 'Aligned LLM (fine-tuned).' In the top right, the human feedback section shows a teal cylinder labeled 'Human preference data' with arrows pointing right toward two icons: a shield labeled 'Safety reward model' and a thumbs-up labeled 'Helpful reward model.' The human preference data also points downward into the aligned LLM. On the far right, the RLHF section shows a gray box with two stacked items: 'Rejection sampling' and 'Proximity policy optimization,' connected by arrows to the aligned LLM.")
This change matters.
Standard RL depends on clear, predefined rules in the environment. RLHF adapts RL for complex tasks—like language generation—where human preferences are too nuanced to reduce to fixed rules.
The result is a system better aligned with what people consider useful, safe, or contextually appropriate.
What are the security risks of RLHF?

RLHF improves model alignment, but it was never designed as a security control. Because it relies on human judgment and reward models, it introduces new attack surfaces that adversaries can exploit.
Key risks include:
- Misaligned reward models. Human feedback can be inconsistent or biased, leading reward models to reinforce unsafe or unintended behaviors.
- Feedback data poisoning. Malicious raters can manipulate preference signals, skewing model behavior even with a small fraction of poisoned data.
- Exploitable trade-offs. Balancing helpfulness with harmlessness can be gamed, with attackers disguising harmful queries as benign or forcing refusals that reduce usability.
- Over-reliance on alignment. Jailbreak prompts and adversarial inputs can bypass RLHF guardrails, showing that alignment alone is brittle without layered defenses.
- Bias amplification. Human judgments reflect social and cultural biases, which RLHF can reproduce and amplify over time.
These weaknesses carry business implications. Poisoned or manipulated models can expose sensitive data, spread inaccurate information, or deliver unsafe outputs to customers. Beyond immediate misuse, biased or harmful outputs create reputational risk, and regulators may impose penalties if safeguards are lacking.
In short: RLHF is valuable for shaping model behavior, but without complementary defenses such as red teaming, input filtering, and validation, it can create operational, reputational, and regulatory exposure that organizations cannot ignore.
- What Is Generative AI Security? [Explanation/Starter Guide]
- What Is LLM (Large Language Model) Security? | Starter Guide
- Top GenAI Security Challenges: Risks, Issues, & Solutions
- What Is a Prompt Injection Attack? [Examples & Prevention]
- What Is Data Poisoning? [Examples & Prevention]
- What Is AI Red Teaming? Why You Need It and How to Implement