Table of Contents
- What is Data Security Posture Management? DSPM Guide
- 2026 DSPM Adoption Report
- How DSPM Is Evolving: Key Trends to Watch
- Why DSPM Is Critical for Enterprise Data Security
- DSPM Vs. CSPM: Key Differences and How to Choose
- What Is a Data Breach?
- What Is Cloud Data Protection?
- How DSPM Enables XDR and SOAR for Automated, Data-Centric Security
- DSPM Tools: How to Evaluate and Select the Best Option
- How DSPM Combats Toxic Combinations: Enabling Proactive Data-Centric Defense
- How DSPM Enables Continuous Compliance and Data Governance
- DSPM for AI: Navigating Data and AI Compliance Regulations
- What Is Data Exfiltration?
- What Is Data Discovery?
- What Is Data-Centric Security?
- What Is Data Access Governance?
- DSPM Market Size: 2026 Guide
- What Is a Data Flow Diagram?
- What Is Data Movement?
-
What Is Data Detection and Response (DDR)?
- Data Detection and Response Explained
- Why Is DDR Important?
- Improving DSPM Solutions with Dynamic Monitoring
- A Closer Look at Data Detection and Response (DDR)
- How DDR Solutions Work
- How Does DDR Fit into the Cloud Data Security Landscape?
- Does the CISO Agenda Need an Additional Cybersecurity Tool?
- Supporting Innovation Without Sacrificing Security
- DSPM and Data Detection and Response FAQs
- What Is Unstructured Data?
- What Is Structured Data?
- What Is Shadow Data?
What Is Data Classification?
5 min. read
Table of Contents
Data classification — or organizing and categorizing data based on its sensitivity, importance, and predefined criteria — is foundational to data security. It enables organizations to efficiently manage, protect, and handle their data assets by assigning classification levels. In doing so, organizations can prioritize resources and apply security measures tailored to each data category's requirements.
Data Classification Explained
Data classification helps identify and protect sensitive information, such as personally identifiable information (PII), protected health information (PHI), and financial data. By categorizing data according to its level of sensitivity, importance, or other criteria, organizations can effectively protect and handle data assets with security measures appropriate to each data type. Compliance with regulatory standards, such as GDPR, HIPAA, or CCPA, rely heavily on data classification.
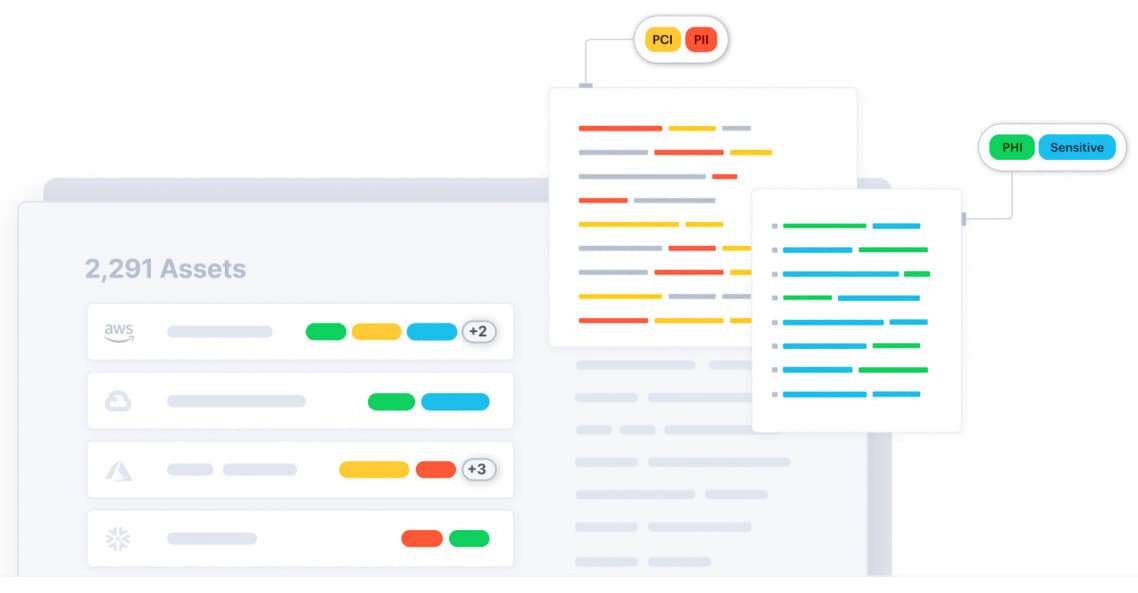
Figure 1: Classifying sensitive data
How Data Classification Works
Performing data classification starts with defining a classification schema, which outlines the categories and criteria for each data type. Common classification levels include public, internal use, restricted, and confidential. Organizations then identify their data assets, both structured and unstructured, and determine the appropriate classification level for each asset.
Automated tools and solutions can assist in the classification process, using advanced algorithms to scan and analyze data, matching it to the defined categories based on content, metadata, or other attributes. Additionally, manual classification involving human intervention may come into play when subject matter expertise is required to evaluate data sensitivity or significance.
Once data is classified, organizations can act on this information by implementing appropriate security controls and policies for each classification level. These measures may include encryption for sensitive data, access controls based on user roles, and data retention policies tailored to each category's requirements.
Integrating data classification into their security practices enables organizations to optimize resource allocation, prioritize protection measures, and make informed decisions about data storage, access controls, data sharing, and retention periods. As in all things cloud security, a proactive and targeted approach mitigates risks and fortifies security posture.
Why Data Classification Matters
Understanding the significance of data classification is pivotal to safeguarding sensitive information and mitigating risks. Security experts can identify the most critical and sensitive assets within an organization’s data ecosystem by classifying data. Gaining this knowledge allows them to allocate appropriate security measures, such as encryption and monitoring, to the highest-risk data categories.
Using data classification, organizations can target security protocols in the most efficient way to achieve the greatest protection of their valuable and sensitive information. Beyond security, different types of data classification enable organizations to align their security efforts to industry-specific regulations and legal requirements.
What Is PCI?
Organizations across industries grapple with the formidable Payment Card Industry (PCI) standards. These standards, established by major credit card companies, serve as a bulwark safeguarding cardholder data during payment transactions. Enter the Payment Card Industry Data Security Standard (PCI DSS), a framework that imposes guidelines and requirements on businesses handling, processing, or storing payment card information.
Compliance with PCI is non-negotiable for entities involved in accepting, transmitting, or housing cardholder data — think merchants, financial institutions, and service providers. The PCI DSS unleashes a barrage of security measures: fortifying network security, employing encryption, tightening access controls, and conducting regular vulnerability assessments.
What Is PII?
When it comes to sensitive information, another area of concern is data that identifies a person, otherwise known as personally identifiable information (PII). The term broadly covers a wide variety of data, including but not limited to:
- Names
- Social security numbers (SSN)
- Addresses
- Phone numbers
- Email addresses
- Financial account details
- Biometric data
PII holds significant value for individuals and organizations, as it is easily exploitable for identity theft, fraud, or other malicious activities. Identifying and safeguarding PII is synonymous to privacy protection and regulatory compliance. Organizations must implement robust security measures, such as encryption, access controls, and data anonymization, to ensure the confidentiality and integrity of PII.
What Is PHI?
In the medical field, protected health information (PHI) covers all sensitive data related to an individual’s health, medical conditions, or treatments, often including PII. This valuable information covers a range of data, including:
- medical records
- diagnostic results
- prescriptions
- health insurance details
- any other personally identifiable health-related data
Managing PHI in the U.S. is challenging, as it’s highly regulated under the Health Insurance Portability and Accountability Act (HIPAA), which ensures the privacy and security standards that care providers must follow. Healthcare workers and organizations must safeguard the confidentiality of PHI to protect patients’ privacy, prevent unauthorized access, and comply with legal requirements. Meeting these requirements involves extreme security measures that include the highest protocols for access controls, encryption, and audit trails.
Challenges of GDPR
For any organizations that store data of citizens or residents of the European Union (EU), they have a more significant data privacy challenge than just identifying specific data types. They must comply with the General Data Protection Regulation (GDPR), which sets strict requirements for organizations handling personal data, and ensure transparency, accountability, and control over how personal information is collected, processed, and stored. As an incentive to comply, GDPR also imposes significant penalties for non-compliance, with fines reaching up to 4% of a company’s global annual revenue or €20 million, whichever is higher, making it extremely cost prohibitive for companies to ignore the mandate.
On top of this, it grants EU citizens and residents various rights, including the right to access their data, the right to be forgotten, and the right to data portability. Each of these rights must be facilitated by organizations storing their data, requiring them to at all times know where the corresponding data is stored, along with who can access it to maintain GDPR compliance. They must also include processes for deleting this data for an individual upon request, which relies upon knowing where the relevant data resides.
Data Classification Levels
Data classification can be done manually or automatically, using a combination of human judgment and advanced algorithms. The data classification levels can vary, ranging from simple labels such as “public,” “confidential,” and “sensitive” to more detailed categories based on specific regulations and industry standards.
Example of data classification levels:
- Confidential Data: This is the most sensitive category and includes data that must be protected at all costs, such as trade secrets, financial information, PII, and confidential business information.
- Internal Use Only: This category includes sensitive data but is not as critical as confidential data, such as employee payroll information, internal memos, and project plans.
- Restricted Data: This category includes sensitive data but is not as critical as confidential data, such as customer information, marketing plans, and pricing information.
- Public Data: This category includes data that is not sensitive and can be freely shared with the public, such as company press releases and marketing materials.
- Archived Data: This category includes data that is no longer actively used but still needs to be retained for legal, regulatory, or historical reasons, such as old financial reports and personnel records.

Figure 2: All-important data security role of data classification.
Data Classification Use Cases
Regardless of the number of compliance mandates an organization must follow, embracing data classification is essential. Implementing data discovery as a best practice can significantly enhance security in a targeted and efficient manner. By understanding the sensitive data within their ecosystem and categorizing it accordingly, organizations can allocate resources more effectively and prioritize security measures accordingly.
Data classification not only aids in compliance efforts but also plays a crucial role in preventing security breaches. By identifying and protecting sensitive data, organizations can mitigate the risks of unauthorized access and potential breaches, avoiding the negative consequences of compromised security. Embracing data classification and utilizing discovery techniques is a proactive step toward safeguarding valuable information and ensuring the integrity and trustworthiness of an organization’s data assets.
What Are Some Data Classification Examples?
Several types of data must be classified for effective data security, as these types are considered sensitive and require protection from unauthorized access, theft, or loss.
- Personal identifiable information includes data that can be used to identify an individual, such as full name, Social Security number, driver's license number, or passport number.
- Financial information refers to data related to financial transactions and accounts, such as credit card numbers, bank account numbers, and investment information.
- Confidential business information involves proprietary data that gives a company a competitive advantage, such as trade secrets, business plans, and market research.
- Health information is data related to a person's health status and medical history, such as diagnoses, treatment plans, and prescription information.
- Intellectual property includes data related to patents, trademarks, copyrights, and trade secrets.
- Government information is classified or restricted by government agencies, such as national security information, law enforcement records, and classified military information.
- Employee Information: This includes data related to employees, such as payroll information, job performance evaluations, and disciplinary records.
These are just a few examples of the classification data vital for better data security. The specific data types that must be classified will vary based on the security requirements of the organization. The goal of data classification, however, remains centered on understanding the level of sensitivity of data and determining the appropriate security measures needed to protect it.

Figure 3: Regulating bodies for at-a-glance understanding of data compliance focus
How Does Data Classification Improve Data Security?
Data classification determines the appropriate security measures needed to protect data from unauthorized access, theft, or loss. As such, it informs many practices in data security. Organizations often leverage data security posture management (DSPM) solutions to automate the classification process and continuously monitor data assets across cloud environments
Risk Assessment
Data classification is used to identify the most critical assets and prioritize protecting sensitive data, which helps organizations to focus their cybersecurity efforts on the areas that require the most attention.
Access Control
Data classification helps organizations to determine who should have access to sensitive data and what level of access they should have. For example, highly sensitive data may only be accessible by a small group of authorized personnel, while less sensitive data may be accessible by a wider group of employees.
Data Encryption
Data classification helps organizations determine which data requires encryption and the necessary level of encryption. For example, some highly sensitive data might require encryption both at rest and in transit, while less sensitive data may only need to be encrypted at rest.
Data Backup and Recovery
Data classification helps organizations determine which data needs to be backed up and how often. For example, highly sensitive data may need to be backed up daily and stored in secure off-site locations, while less sensitive data may only need to be backed up weekly.
Compliance
Data classification is also used to ensure compliance with data protection regulations such as the GDPR, the HIPAA, or the PCI DSS. These regulations often require organizations to implement specific security measures for protecting sensitive data, and data classification is the first step in determining which data falls into this category.
Data Classification FAQs
The types of data classification include public, internal use, restricted, and confidential which is the most sensitive category, typically including personally identifiable information and trade secrets.
Data classification examples include PII, PHI, financial data, intellectual property such as trade secrets and patents, and government information.
Data privacy compliance refers to an organization's adherence to laws, regulations, and industry standards governing the collection, storage, processing, and sharing of personal and sensitive data.
Compliance requirements vary depending on the jurisdiction, sector, and type of data involved, with examples including the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), and
GDPR compliance refers to an organization's adherence to the European Union's General Data Protection Regulation, a comprehensive data privacy law that came into effect in May 2018. The regulation applies to any organization that processes the personal data of EU residents, regardless of its geographical location.
GDPR compliance involves implementing data protection measures such as data minimization, encryption, and pseudonymization, as well as ensuring that data subjects' rights, including the right to access, rectification, and erasure, are respected. Organizations must also conduct data protection impact assessments, appoint a Data Protection Officer if required, and report data breaches within 72 hours.
HIPAA regulations refer to the Health Insurance Portability and Accountability Act, a U.S. federal law that establishes standards for protecting the privacy and security of patients' health information. The regulations consist of the Privacy Rule, which governs the use and disclosure of PHI, and the Security Rule, which sets specific requirements for safeguarding the confidentiality, integrity, and availability of electronic PHI.
Organizations handling PHI, such as healthcare providers and their business associates, must implement administrative, physical, and technical safeguards, as well as ensure proper training and risk management practices to achieve HIPAA compliance.